
Die Vernetzung war von Anfang an ein wichtiger Bestandteil von Rechenzentren. Wie das System Ressourcen im gesamten Unternehmensökosystem verbindet, macht einen großen Unterschied darin, wie effizient und effektiv das System ist.
In den letzten etwa zehn Jahren haben sich Unternehmensrechenzentren als Reaktion auf eine Reihe technologischer Fortschritte wie Cloud, Edge Computing, Containerisierung, Cloud-native Computing usw. rasant weiterentwickelt. Um wettbewerbsfähig zu bleiben, müssen Unternehmen intelligente und flexible Speicherarchitekturen bereitstellen, die hochgradig automatisiert sind und in der Lage sind, Daten effizient und schnell durch das gesamte System zu bewegen.
In diesem Artikel werfen wir einen Blick auf zwei spezifische Faktoren, die den rasanten Anstieg vorantreiben Entwicklung der Rechenzentrumsspeicherung Vernetzung:

Compute Express Link (CXL)
CXL ist eine Cache-kohärente Verbindung nach offenem Standard, die den Speicher mit Verarbeitungsaufgaben in Servern und Speicher verbindet. Es baut auf der bereits schnellen PCI Express (PCIe)-Verbindung auf, die schon seit einiger Zeit Standard ist.
Die neueste PCIe-Iteration, Gen5, kann potenziell CPUs und Peripheriegeräte mit Geschwindigkeiten von bis zu 32 Gigatransfers pro Sekunde (GT/s) verbinden. PCIe weist jedoch einige Einschränkungen auf, die die Datenzugriffsgeschwindigkeiten heutzutage beeinträchtigen. Eine dieser Einschränkungen besteht darin, dass getrennte Speicher nicht sehr effizient verwaltet werden. Ein weiterer Grund ist, dass die Latenz von PCIe zu hoch ist, um den Speicher effizient auf mehrere Geräte zu verteilen.
Bedenken Sie Folgendes: Viele der heutigen Server, insbesondere die von Hyperscalern, enthalten Komponenten, die über einen eigenen integrierten Speicher verfügen. Neben dem an einen Host-Prozessor angeschlossenen Hauptspeicher können auch intelligente Netzwerkkarten, GPUs und Speicher-SSDs vorhanden sein. Diese Geräte verfügen über Speicher-Caches, die oft nicht ausreichend ausgelastet sind, teilweise sogar erheblich. Das bedeutet, dass im gesamten System viel Speicher ungenutzt bleibt. Multiplizieren Sie den gesamten ungenutzten Speicher mit Tausenden von Servern, und es wird von Bedeutung. Diese Caches können normalerweise nicht interagieren, es sei denn, sie verfügen über ein Tool, um sie zu verbinden.
CXL überwindet diese Einschränkungen. CXL wurde teilweise entwickelt, um die Unfähigkeit des Speichers der Speicherklasse zu beheben, zahlreiche Verarbeitungsknoten angemessen zu verarbeiten. Es nutzt die physische Verbindungsschicht und die elektrische Konfiguration von PCIe, weist jedoch eine viel geringere Latenz beim Zugriff auf Daten aus dem Speicher auf. Es sorgt für Cache-Kohärenz zwischen Host-Servern und anderen Geräten, sodass der Speicher im gesamten System als ein einziger zugänglicher Pool behandelt wird. Diese Speicherpools können die Kapazität erheblich erhöhen und können direkt mit CPU- und GPU-Prozessoren sowie Computerspeichern und intelligenten Netzwerkschnittstellenkarten (NICs) verbunden werden.
Da CXL-kompatible Systeme gerade erst auf den Markt kommen, hat die Technologie das Potenzial, die Art und Weise, wie Plattformen und Rechenzentren entworfen und betrieben werden, zu verändern. Die Branche wird sich nach und nach von dem Konzept verabschieden, dass jeder Knoten über einen eigenen Speicher und eine eigene Verarbeitung verfügt – hin zu einer disaggregierten Infrastruktur, die Arbeitslasten Ressourcen aus einem großen einzelnen Speicherpool zuweist, der das gesamte Ökosystem, einschließlich einer beliebigen Anzahl von GPUs, CPUs usw., bedient Rechenspeicher. Dadurch können Unternehmen Rechenzentren mit enormen Speicherkapazitäten aufbauen.

Vorteile von CXL
Mit CXL sind Unternehmen nicht mehr auf proprietäre Verbindungen zwischen Speicher, Rechenleistung, Hauptspeicher und Speicher der Speicherklasse beschränkt – mehrere Prozessoren können sich daher größere Speicherpools teilen als zuvor.
CXL ermöglicht es Unternehmen außerdem, über DRAM hinaus größere Kapazität und Bandbreite zu erreichen. Mithilfe eines an CXL angeschlossenen Geräts können sie Speicher zu einem CPU- oder GPU-Hostprozessor hinzufügen. Das bedeutet, dass CPU und GPU Zugriff auf Terabytes an Speicher mit DRAM-Geschwindigkeit haben könnten.
Auch wenn die Latenz von Speicher und DRAM nicht wirklich vergleichbar ist (z. B. 80 Mikrosekunden bzw. 0,25 Mikrosekunden), besteht immer noch keine wirkliche Notwendigkeit, alles in DRAM zu verlagern. Mithilfe von CXL kann das System die benötigten Daten von der SSD über die vorhandene, in die CPU integrierte Speicherhierarchie abrufen. Das bedeutet, dass kein Dateisystem und alle dazugehörigen Schichten erforderlich sind, was zu einer Latenz von 10 bis 20 Mikrosekunden führen kann.
Natürlich werden Dateisysteme nicht so schnell verschwinden, denn sie erfüllen einen wertvollen Zweck für die allgemeine Datenverarbeitung. Aber über CXL können Unternehmen Pools von SSD-Speicherdaten erstellen, die die Rechenkapazitäten zu einem Bruchteil der Kosten von DRAM erweitern. Anstatt also auf einen Datensatz beschränkt zu sein, der in 128 GB DRAM passt, können Unternehmen nun Hunderte von TB NVMe-SSD-Speicher mit PCIe-Gen6-Geschwindigkeit betreiben.
Zu den weiteren Vorteilen von CXL gehören:
-
-
- Open Source, branchenweiter Standard für speicherintensive Anwendungen
- Ermöglicht heterogenes Computing und verbessert die Ressourcennutzung auf lokalen und Cloud-Plattformen
- Verbessert die Zusammenarbeit durch die schnelle und effiziente gemeinsame Nutzung von Daten zwischen Servern und Anwendungen
- Ermöglicht Teams die gleichzeitige Ausführung von Prozessen auf denselben In-Memory-Datensätzen
-

CXL-Anwendungsfälle
Da es einen großen Speicherpool ermöglicht, der sich über ein gesamtes System erstreckt, eignet sich CXL gut für Workloads, die große Mengen an In-Memory-Daten benötigen. Zu diesen Arbeitsbelastungen gehören:
-
-
- KI, maschinelles Lernen und Datenanalyse – Schulung für Deep Learning, interaktive integrierte Entwicklungsumgebungen (IDEs)
- Online-Transaktionsverarbeitung (OLTP) und Online-Analyseverarbeitung (OLAP)
- Medien und Unterhaltung – grafische Simulationen, Rendering und Spezialeffekte
- Genetische Forschung – Sequenzierung und Assemblierungsanalytik
- Electronic Design Automation (EDA) und Computer Aided Engineering (CAE) – Modellierung und Simulationen
- Finanzdienstleistungsanwendungen – Unterstützung für Entscheidungen und Analysen
- Hochleistungsrechnen – Modellierung und Simulation
- Cloud – Snapshots von virtuellen Kernel-Maschinen (KVMs), Ad-hoc-Instanzen für Arbeitslasten, die nicht fehlertolerant sind
-
Hyperscaler und Cloud-Service-Provider werden aufgrund seiner ultraschnellen Skalierungs- und Bereitstellungsfunktionen wahrscheinlich zu CXL tendieren.
NVMe über Fabric (NVMe-oF)
Transportprotokolle für Storage Area Networks (SANs) haben sich im Laufe der Zeit erheblich weiterentwickelt. Für die Verbindung mit HDD-basierten SANs wurden verschiedene Protokolle entwickelt, z. B. iSCSI, Serial Attached SCSI (SAS) und Fibre Channel Protocol (FCP). Diese Protokolle lieferten ausreichend Leistung für Festplatten, reichen jedoch nicht für SSDs aus. Nachdem der HDD-Engpass durch den Austausch von HDDs durch SSDs beseitigt wurde, wurden die Protokolle selbst zum Flaschenhals. NAND-Flash-basierter Speicher benötigte etwas mehr, damit Unternehmen alle Vorteile der Technologie nutzen können.
Da Datenpools immer größer werden, können sie nicht immer über eine PCIe-Fabric verbunden werden, die bis zu einer physischen Entfernung von etwa 100 Fuß effektiv ist. Darüber hinaus ist noch etwas anderes erforderlich. Hier kommt NVMe over Fabrics (NVMe-oF) ins Spiel. Das Protokoll fungiert als Nachrichtenschicht, um die Datenübertragung zwischen einem Hostserver und einem Solid-State-Speicher oder einem anderen Gerät zu ermöglichen – oder über ein erweitertes Netzwerk, das auch als Fabric bezeichnet wird.
NVMe-oF ist ideal für Blockspeicher, der Flash- oder anderen SSD-Speicher verwendet. Es bietet niedrige Latenz bei hoher Leistung sowie einfache Skalierbarkeit und Unterstützung für die vier wichtigsten Netzwerkprotokolle: Fibre Channel, iWARP, InfiniBand, RDMA, RoCE (RDMA over Converged Ethernet) und TCP/IP. NVMe-oF ist besser als Network-Attached Storage (NAS), da es viel weniger Overhead verursacht. Heutzutage ist es aus Sicht der Latenz so gut wie es nur geht, sobald die Entfernungen für PCIe zu groß werden.
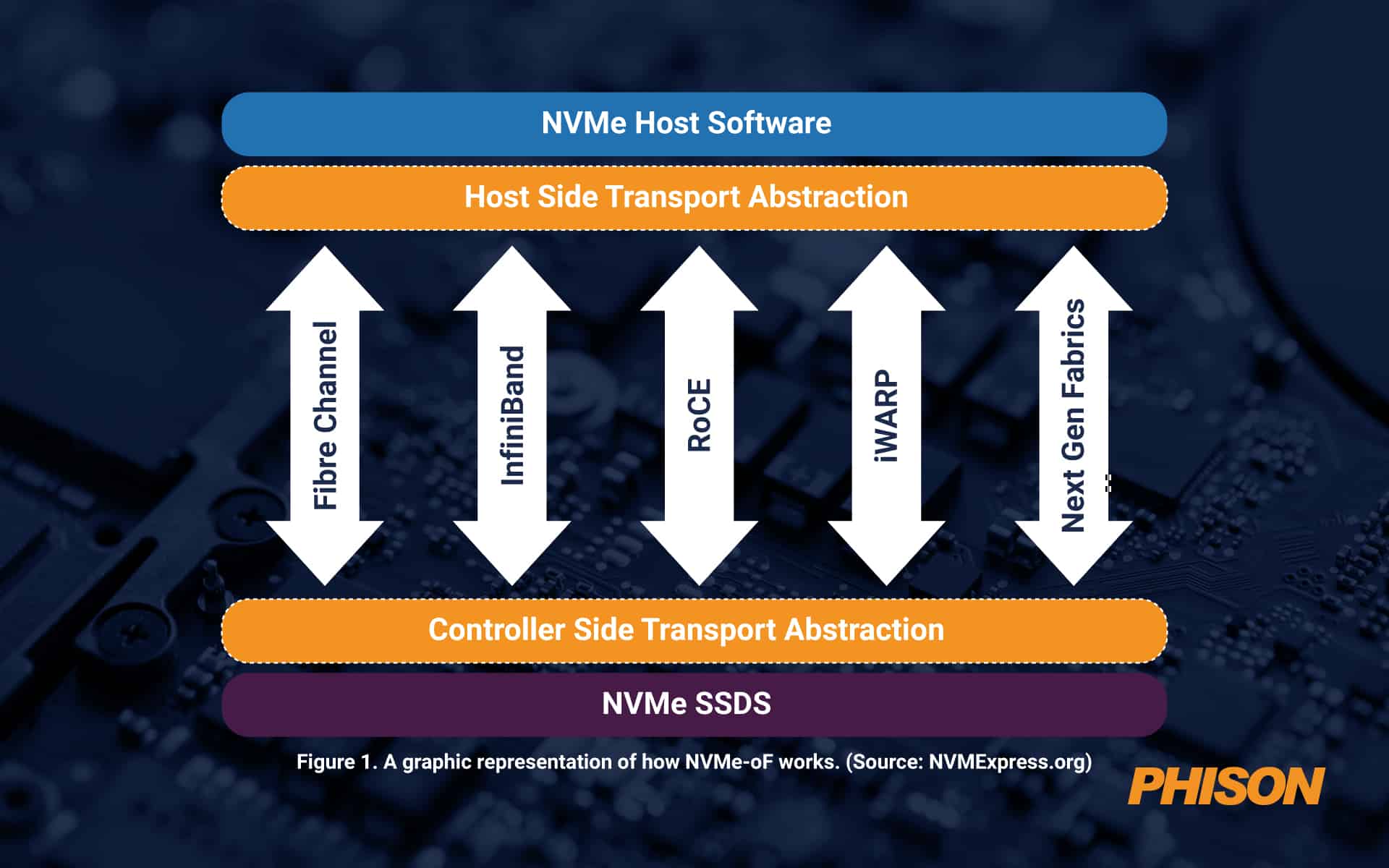
Abbildung 1. Eine grafische Darstellung der Funktionsweise von NVMe-oF. (Quelle: NVMExpress.org)
Vorteile von NVMe-oF
NVMe-oF bietet die Möglichkeit, ein Hochleistungsspeichernetzwerk mit geringen Latenzen zu erstellen, ähnlich wie Direct Attached Storage (DAS). Das bedeutet, dass Server im gesamten System Flash-Geräte nach Bedarf gemeinsam nutzen können. Im Wesentlichen können Unternehmen die schnelle Leistung eines Flash-basierten Arrays in Kombination mit den Vorteilen von gemeinsam genutztem Speicher oder Netzwerkspeicher nutzen.
Mithilfe von NVMe-oF können Unternehmen ein Speichersystem erstellen, das von Servern getrennt und als einzelner gemeinsamer Pool verwaltet wird. Das bedeutet, dass die IT Speicherressourcen detaillierter und flexibler als je zuvor bereitstellen kann.
Weitere Vorteile sind:
-
-
- Extrem niedrige Latenz
- Schnellere Konnektivität zwischen Serveranwendungen und Speicher
- Effizientere CPU-Auslastung
- Höhere Auslastungsraten
- Einfachere Verwaltung
- Erhöhte Gesamtleistung
- Zusätzliche parallele Anfragen
- Verbesserte Redundanz und Ausfallsicherheit
-
NVMe-oF-Anwendungsfälle
Das NVMe-oF-Protokoll ist ideal für jeden Anwendungsfall, bei dem Daten vom Speicher über ein Netzwerk auf beliebige Flash-Medien verschoben werden. Heutzutage nutzen viele Unternehmen NVMe-oF in Fällen, in denen hohe Leistung von entscheidender Bedeutung ist, wie etwa bei KI oder maschinellem Lernen, Datenanalysen und Hochleistungsrechnen. Es eignet sich auch gut für transaktionale Workloads.

Phison bietet hochmoderne SSDs für die modernen Anforderungen von heute
Da die Datenübertragungsgeschwindigkeit zunimmt, Phison den Kunden bieten kann Angepasste PCIe-Gen5-SSD-Plattformen um in ihren Anwendungen optimale Leistungen zu erbringen. Tatsächlich hat Phison kürzlich eine der ersten Gen5-SSDs der Branche herausgebracht. der Phison E26, das die branchenweit höchsten Geschwindigkeiten für die heutigen großen und komplexen Arbeitslasten bietet.
Darüber hinaus investiert Phison kontinuierlich stark in Forschung und Entwicklung, um SSD-Lösungen zu entwickeln, die auf neue Technologien abgestimmt sind und sicherstellen, dass seine Produkte zukunftssicher und bereit sind, die Innovationen von morgen voranzutreiben.

Häufig gestellte Fragen (FAQ):
Warum ist eine disaggregierte Infrastruktur für Rechenzentren wichtig?
Disaggregierte Infrastruktur ermöglicht Speicher und berechnen unabhängig zu skalieren. Anstatt Zuteilung festen Speicher pro Server, Ressourcen werden je nach Bedarf aus einem gemeinsamen Pool bezogen. Diese Flexibilität ermöglicht Hyperscaler und Cloud-Anbieter, um dynamische Workloads wie KI-Training, Simulation oder Echtzeitanalysen ohne Überbereitstellung zu unterstützen.
Wie schneidet NVMe-oF im Vergleich zu herkömmlichen SAN-Protokollen ab?
Im Gegensatz zu SAS, iSCSI oder Faser Kanal, welche waren optimiert für HDDs, NVMe-oF ist für Flash-basierte Medien konzipiert. Es bietet nahezu lokale Speicherlatenz über ein Netzwerk, skaliert effizient über Distanzen und unterstützt Hochleistungsprotokolle wie RoCE und TCP/IP. Damit ist es ideal für SSD-zentrierte Architekturen.
Was macht Phison-SSDs mit Speichernetzwerken der nächsten Generation kompatibel?
Die PCIe Gen5 SSDs von Phison, einschließlich der Serien E26 und Pascari, sind auf hohen Durchsatz, geringe Latenz und robuste Ausdauer ausgelegt, Schlüsselanforderungen für CXL und NVMe-oF Anwendungsfälle. Sie sind optimiert für KI-Workloads, große Datenübertragungen und Fabric-basierte Speicherbereitstellungen mit geringer Latenz.
Was sind die Latenzvorteile von CXL und NVMe-oF?
CXL reduziert die Speicherzugriffslatenz im Vergleich zu PCIe erheblich und ermöglicht so eine DRAM-Geschwindigkeitsleistung für gepoolten SSD-Speicher. NVMe-oF minimiert den Netzwerk-Overhead und bietet eine Latenz nahe DAS, selbst über größere Entfernungen, Dies macht beide Technologien für zeitkritische Datenoperationen von entscheidender Bedeutung.
Wie macht Phison seine SSD-Lösungen zukunftssicher?
Durch cweiterInvestitionen in Forschung und Entwicklung und eine enge Abstimmung mit neuen Standards wie CXL und NVMe-oF, Phison stellt sicher, dass seine SSDs bleiben Bereit für sich entwickelnde Arbeitslasten. Das Unternehmen entwickelt anpassbare Firmware- und Hardware-Stacks, um den unterschiedlichen Leistungs-, Ausdauer- und Integrationsanforderungen von Unternehmen gerecht zu werden.






