
Networking has been a critical component of data centers since the beginning. How the system connects resources across the enterprise ecosystem makes a big difference in how efficient and effective the system is.
Over the past 10 years or so, enterprise data centers have been evolving rapidly in response to a number of technological advances, such as the cloud, edge computing, containerization, cloud-native computing and so on. To stay competitive, organizations need to deploy smart and flexible storage architectures that are highly automated and capable of moving data through the entire system efficiently and quickly.
In this article, we’ll take a look at two specific factors that are driving the rapid evolution of data center storage networking:

Compute Express Link (CXL)
CXL is an open standard cache-coherent interconnect that links memory to processing tasks in servers and storage. It builds on the already-fast PCI Express (PCIe) interconnect, which has been a standard for some time now.
The latest PCIe iteration, Gen5, can potentially connect CPUs and peripherals at speeds up to 32 gigatransfers per second (GT/s). PCIe has some limitations, however, that hinder data access speeds today. One of those limitations is that it doesn’t manage separated stores of memory very efficiently. Another is that the latency of PCIe is too high to efficiently share memory across several devices.
Consider this: many of today’s servers, especially those of hyperscalers, contain components that come with their own on-board memory. Besides the main memory attached to a host processor, there also might be smart NICs, GPUs and storage SSDs. These devices have memory caches that often are underutilized, some by a lot. That means that throughout that system, there is a lot of memory lying idle. Multiply all that unused memory by thousands of servers and it becomes significant. These caches typically can’t interact unless they have a tool to connect them.
CXL overcomes these limitations. Developed partly to address the inability of storage-class memory to adequately handle numerous processing nodes, CXL utilizes the physical connection layer and electrical configuration of PCIe but has much lower latency when accessing data from memory. It provides cache coherency between host servers and other devices, so memory across the entire system is treated as a single accessible pool. These memory pools can significantly increase capacity and can link directly to CPU and GPU processors, as well as computational storage and intelligent network interface cards (NICs).
With CXL-compatible systems just now beginning to launch, the technology has the potential to transform how platforms and data centers are designed and run. The industry will gradually shift away from the concept of each node having its own memory and processing—in favor of disaggregated infrastructure that assigns resources to workloads from a large single pool of memory that serves the entire ecosystem, including any number of GPUs, CPUs and computational storage. That allows organizations to build data centers with capacities of massive volumes of memory.

Benefits of CXL
With CXL, organizations are no longer confined to proprietary interconnects between storage, compute, memory and storage-class memory—so multiple processors are able to share bigger pools of memory than they could before.
CXL also enables organizations to achieve greater capacity and bandwidth beyond DRAM. Using a CXL-attached device, they can add memory to a CPU or GPU host processor. That means the CPU and GPU could have access to terabytes of storage at DRAM speed.
While the latency of storage vs. DRAM isn’t really comparable (say, 80 microseconds to .25 microsecond respectively), there’s still no real need to move everything into DRAM. Using CXL, the system can fetch the data it needs from the SSD through the existing memory hierarchy built into the CPU—meaning there’s no need for a file system and all the accompanying layers, which can add 10 to 20 microseconds of latency.
File systems aren’t going away anytime soon, of course, because they serve a valuable purpose for general computing. But through CXL, organizations can create pools of SSD storage data that augment compute capabilities at a fraction of the cost of DRAM. So now, instead of being limited to a dataset that fits into 128 GB of DRAM, organizations can have hundreds of TBs of NVMe SSD storage running at PCIe Gen6 speeds.
Other benefits of CXL include:
-
-
- Open source, industrywide standard designed for memory-intensive applications
- Enables heterogeneous computing and improves resource utilization across on-premises and cloud platforms
- Enhances collaboration by enabling fast, efficient sharing of data across servers and applications
- Allows teams to run concurrent processes on the same in-memory datasets
-

CXL use cases
Because it enables a large pool of memory that spans across an entire system, CXL is well-suited for workloads that need massive amount of in-memory data. These workloads include:
-
-
- AI, machine learning and data analytics – training for deep learning, interactive integrated development environments (IDEs)
- Online transaction processing (OLTP) and online analytical processing (OLAP)
- Media and entertainment – graphic simulations, rendering, and special effects
- Genetic research – sequencing and assembly analytics
- Electronic Design Automation (EDA) and Computer Aided Engineering (CAE) – modeling and simulations
- Financial services applications – support for decisions and analytics
- High-performance computing – modeling and simulation
- Cloud – snapshots of kernel virtual machines (KVMs), ad hoc instances for workloads that aren’t fault-tolerant
-
Hyperscalers and cloud service providers will likely gravitate toward CXL because of its ultra-fast scaling and provisioning capabilities.
NVMe over fabric (NVMe-oF)
Transport protocols for storage area networks (SANs) have evolved significantly over time. Different protocols were developed to connect to HDD-based SANs, such as iSCSI, Serial attached SCSI (SAS) and Fibre Channel Protocol (FCP). These protocols delivered enough performance for HDDs but aren’t sufficient for SSDs. After the HDD bottleneck was removed by replacing HDDs with SSDs, the protocols themselves became the bottleneck. NAND flash-based storage needed something more to help organizations reap all the benefits of the technology.
As pools of data get larger in size, they can’t always be connected over a PCIe fabric, which are effective to about 100 feet of physical distance. Beyond that, something else is needed. That’s where NVMe over Fabrics (NVMe-oF) comes in. The protocol acts as a messaging layer to enable data transfer between a host server and solid state storage or other device—or over an extended network, which is also called a fabric.
NVMe-oF is ideal for block storage that uses flash or other SSD storage. It delivers low latency with high performance, as well as simple scalability and support for the four main network protocols, which are Fibre Channel, iWARP, InfiniBand, RDMA, RoCE (RDMA over Converged Ethernet) and TCP/IP. NVMe-oF is better than network-attached storage (NAS) because it has a lot less overhead. Today, it’s as good as it can get from a latency perspective once distances become too big for PCIe.
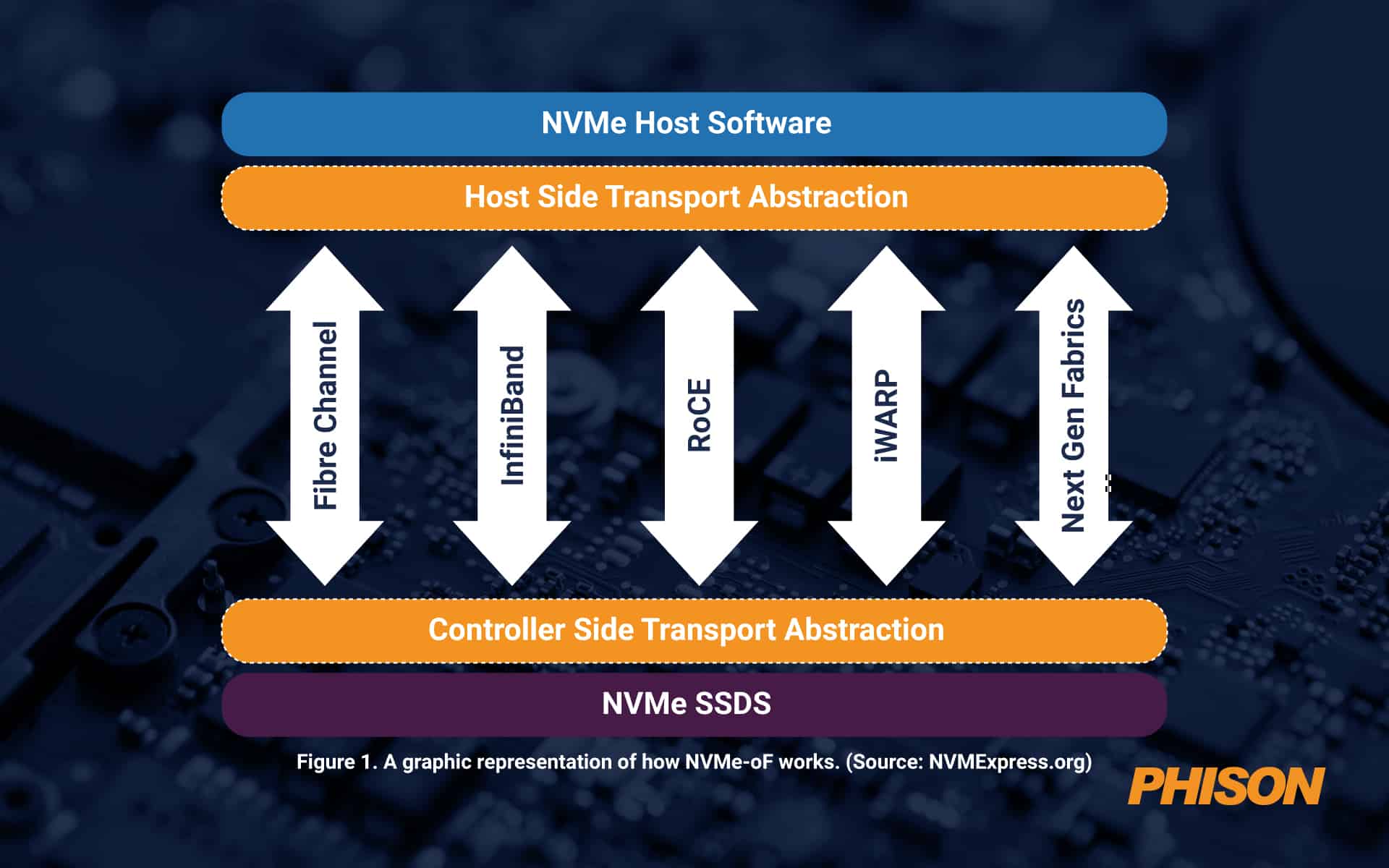
Figure 1. A graphic representation of how NVMe-oF works. (Source: NVMExpress.org)
Benefits of NVMe-oF
NVMe-oF delivers the ability to create a high-performance storage network with low latencies similar to direct attached storage (DAS). That means servers across the system can share flash devices as needed. In essence, organizations can get the speedy performance of a flash-based array combined with the advantages of shared or network storage.
Using NVMe-oF, organizations can create a storage system that’s disaggregated from servers and managed as a single shared pool. That means IT can provision storage resources more granularly and flexibly than ever before.
Other benefits include:
-
-
- Ultra-low latency
- Faster connectivity between server applications and storage
- More efficient CPU usage
- Higher utilization rates
- Easier management
- Increased overall performance
- Additional parallel requests
- Improved redundancy and resilience
-
NVMe-oF use cases
The NVMe-oF protocol is ideal for any use case that involves moving data from storage over a network to any flash media. Today, many organizations are using NVMe-oF in cases where high performance is critical, such as AI or machine learning, data analytics and high-performance computing. It can also be well-suited for transactional workloads.

Phison offers cutting-edge SSDs for today’s advanced needs
As data transfer speeds increase, Phison can provide customers with PCIe Gen5 SSD platforms customized to perform optimally in their applications. In fact, Phison recently released one of the industry’s first Gen5 SSDs, the Phison E26, which delivers the industry’s fastest speeds for today’s large and complex workloads.
In addition, Phison continually invests heavily in R&D to create SSD solutions that align with emerging technologies and ensure that its products are future-proofed and ready to power tomorrow’s innovations.

Frequently Asked Questions (FAQ) :
Why is disaggregated infrastructure important for data centers?
Disaggregated infrastructure allows memory and compute to scale independently. Instead of allocating fixed memory per server, resources are pulled from a common pool as needed. This flexibility enables hyperscalers and cloud providers to support dynamic workloads like AI training, simulation, or real-time analytics without over-provisioning.
How does NVMe-oF compare to traditional SAN protocols?
Unlike SAS, iSCSI, or Fibre Channel, which were optimized for HDDs, NVMe-oF is designed for flash-based media. It provides near-local storage latency over a network, scales efficiently over distance, and supports high-performance protocols like RoCE and TCP/IP, making it ideal for SSD-centric architectures.
What makes Phison SSDs compatible with next-gen storage networking?
Phison’s PCIe Gen5 SSDs, including the E26 and Pascari series, are engineered for high throughput, low latency, and robust endurance, key requirements for CXL and NVMe-oF use cases. They’re optimized for AI workloads, large data transfers, and low-latency fabric-based storage deployments.
What are the latency advantages of CXL and NVMe-oF?
CXL significantly reduces memory access latency compared to PCIe, allowing DRAM-speed performance for pooled SSD storage. NVMe-oF minimizes network overhead, offering near-DAS latency even over extended distances, making both technologies critical for time-sensitive data operations.
How does Phison future-proof its SSD solutions?
Through continuous investment in R&D and tight alignment with emerging standards like CXL and NVMe-oF, Phison ensures its SSDs remain ready for evolving workloads. The company designs customizable firmware and hardware stacks to meet diverse enterprise performance, endurance, and integration needs.






