
Today’s enterprises run on information. As an organization strives for complete digital transformation, virtually every aspect of doing business results in new data—from employee hires and customer transactions to inventory management and service requests. The end result is a continually expanding amount of information. All of which needs to be stored, managed, organized and made accessible to the right people or applications at the right time.
Enormous growth in enterprise data is occurring across all industries. One recent survey found that respondents were experiencing an average of 63% growth in data volume each month.
This tsunami of information will only increase as organizations continue to adopt the remote and hybrid work styles that were so critical during the COVID pandemic. Artificial intelligence (AI) and machine learning (ML) are also driving the data storm, as are the Internet of Things, data analytics and edge computing.
Organizations are collecting data from more sources than ever before. The same survey reported that among respondents, the mean number of data sources was 400. Over 20% of respondents said they were gathering data from 1000 or more data sources. That’s a lot of information to store and manage. It isn’t an easy task and it’s getting more complex all the time.
Smart, forward-looking organizations will persist until they find the right solutions that help them get the most value out of their data. The reason is that their data can generate incredible insights into how they do business, serve customers, retain workers and more. And those insights can lead to game-changing shifts in processes and operations to give companies a serious competitive edge.
The rise of unstructured data
Most of the data flooding enterprises is unstructured. While experts don’t agree on the exact number, they typically estimate that unstructured data makes up 80% to 90% of enterprise data.
Unstructured data doesn’t conform to a spreadsheet-type format like structured data does. Instead of fitting neatly into a database of rows and columns, unstructured data can be in a wide range of formats—including video and audio files, email content, social media posts, satellite data, traffic data captured by automated sensors and more.
Because it’s unstructured, this information is tough to organize, parse and analyze. With the right data analytics or AI systems, however, organizations can process that data. Analytics systems can make connections between the information generated by disparate sources to identify areas that need improvement.

Not all data is equally valuable
Many organizations struggle with knowing how to effectively leverage their data, structured or unstructured. A 2020 survey found that 68% of data available to enterprises actually doesn’t get used at all.
While that sounds like a lot of data is going to waste, it might not present the whole picture. The truth is, not all data is critically valuable to an organization. Some data isn’t valuable at all. This is called “dark data,” defined by Gartner as “information assets that organizations collect, process and store during regular business activities, but are not generally used for other purposes such as analytics, business relationships and direct monetization.”
Keeping dark data can needlessly increase storage costs and result in greater risk to an organization. Data must be secured, so why increase your vulnerability hanging on to data you don’t need?
The trick is in knowing which data to keep and which to jettison. That requires a whole new approach to data management.
As Seagate CIO Ravi Naik said in a recent interview: “Businesses must rethink data management strategies and deploy technologies that allow them to capture the right data at the start of its lifecycle, to safely store the data, and to access it seamlessly when needed.”

Determine which data goes where
A common way to decide where data should be stored is to consider storage tiering. Typically, organizations have four classes of data: mission-critical, hot, warm and cold. Then there are anywhere from four to six storage tiers that define which storage media are used, ranging from ultra-fast to slow.
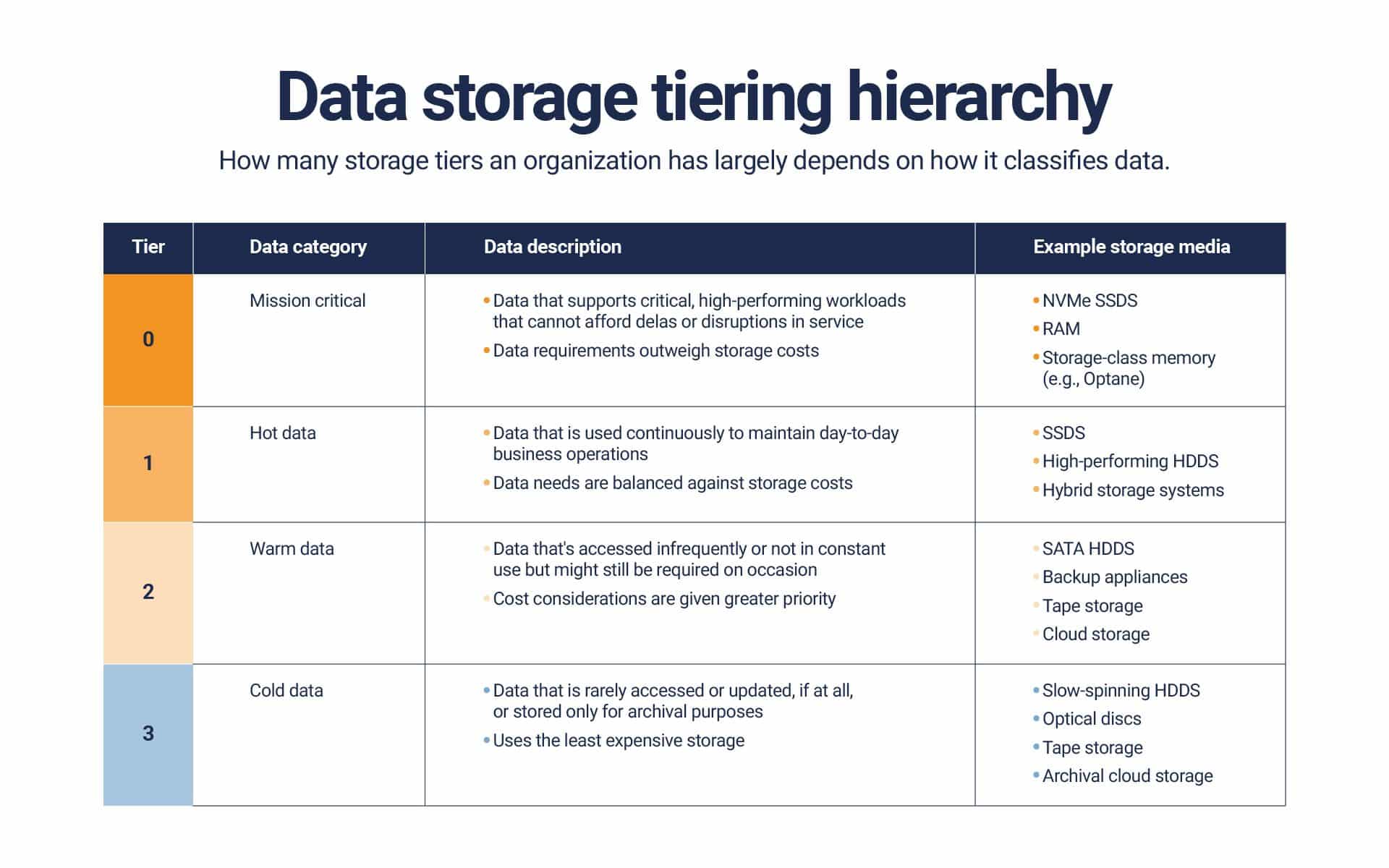
Finding the right type of storage for your data requires knowing how often it needs to be accessed and what it’s used for. Source: TechTarget]
How Phison can help
Phison believes in the superior power of solid state drives (SSDs). As the world’s largest private-label NAND storage and IP service company, Phison manufactured 90% of retail-branded Gen4 SSDs worldwide in 2020.
The company’s enterprise SSD storage solutions provide the best combination of performance and low power consumption capabilities that allow organizations to store and access their most important data quickly and easily—for even the most critical workloads.
Now that Seagate has announced a partnership with Phison to make its enterprise SSDs, there will be even more options for IT managers who want the best-performing storage in their data centers to enable AI applications and build out hot and warm data installations. For mission-critical and hot data installations, Phison and Seagate have created the X1 SSD platform that offers a best-in-class combination of PCIe Gen4x4 dual port speeds and low power consumption. For warm data storage, Phison offers the world’s highest-capacity 2.5″ SATA at 15.36 TB QLC for enterprise SSDs. It delivers performance that exceeds HDDs by 20 times for random write IOPS and 50 times in random read IOPs. Phison SSDs also provide high rack density and low power consumption to help lower costs in the data center

Frequently Asked Questions (FAQ) :
What is ‘dark data’ and why does it matter?
Dark data refers to stored information that organizations do not use. It adds cost, complexity, and risk, especially since all data must be protected. Identifying and purging nonessential data helps streamline storage operations and enhance security.
How does storage tiering optimize data management?
Tiering classifies data into categories like mission-critical, hot, warm, or cold based on access frequency. Matching each type to the right SSD tier (e.g., Gen4 NVMe for hot data, QLC SATA for warm) ensures performance without overpaying for unused speed.
What distinguishes Phison's Pascari Enterprise SSDs?
Pascari SSDs combine low power draw with high throughput, optimized for data center, AI, and boot server environments. Phison’s co-design capabilities allow for storage that fits precise enterprise workloads while minimizing total cost of ownership.
What is special about the Pascari X1 SSD?
Designed for mission-critical and hot data, the Pascari X1 delivers dual-port PCIe Gen4x4 performance with low power usage, ideal for applications where latency and uptime are non-negotiable.
How does Phison address warm data storage?
For warm-tier storage, Phison’s 15.36TB 2.5″ SATA QLC SSD outperforms HDDs significantly: 20x faster in random writes and 50x in random reads. This makes it ideal for high-density storage with lower power costs.






