
从一开始,网络就一直是数据中心的关键组成部分。系统如何连接整个企业生态系统的资源对于系统的效率和效果有很大影响。
过去10年左右,企业数据中心随着云、边缘计算、容器化、云原生计算等多项技术进步而快速发展。为了保持竞争力,组织需要部署智能且灵活的存储架构,这些架构高度自动化,并且能够在整个系统中高效、快速地移动数据。
在本文中,我们将探讨推动这一快速发展的两个具体因素。 数据中心存储的演变 联网:

计算快速链路 (CXL)
CXL 是一种开放标准缓存一致性互连,将内存链接到服务器和存储中的处理任务。它建立在已经很快的 PCI Express (PCIe) 互连之上,该互连已经成为标准一段时间了。
最新的 PCIe 迭代 Gen5 可以以高达每秒 32 千兆传输 (GT/s) 的速度连接 CPU 和外设。然而,PCIe 有一些限制,阻碍了当今的数据访问速度。这些限制之一是它不能非常有效地管理独立的内存存储。另一个问题是 PCIe 的延迟太高,无法在多个设备之间有效共享内存。
考虑一下:当今的许多服务器,尤其是超大规模服务器,都包含带有自己的板载内存的组件。除了连接到主机处理器的主内存之外,还可能有智能网卡、GPU 和存储 SSD。这些设备的内存缓存通常未得到充分利用,有些甚至利用率很高。这意味着在整个系统中,有大量内存处于闲置状态。将所有未使用的内存乘以数千台服务器,就会变得非常重要。这些缓存通常无法交互,除非它们有连接它们的工具。
CXL 克服了这些限制。 CXL 的开发部分是为了解决存储级内存无法充分处理大量处理节点的问题,它利用 PCIe 的物理连接层和电气配置,但从内存访问数据时的延迟要低得多。它提供主机服务器和其他设备之间的缓存一致性,因此整个系统的内存被视为单个可访问池。这些内存池可以显着增加容量,并可以直接链接到 CPU 和 GPU 处理器,以及计算存储和智能网络接口卡 (NIC)。
随着 CXL 兼容系统刚刚开始推出,该技术有可能改变平台和数据中心的设计和运行方式。该行业将逐渐放弃每个节点拥有自己的内存和处理能力的概念,转而采用分散的基础设施,从服务于整个生态系统的大型单一内存池中为工作负载分配资源,包括任意数量的 GPU、CPU 和计算存储。这使得组织能够构建具有大量内存的数据中心。

CXL 的好处
借助 CXL,组织不再局限于存储、计算、内存和存储级内存之间的专有互连,因此多个处理器能够共享比以前更大的内存池。
CXL 还使组织能够获得超越 DRAM 的更大容量和带宽。使用连接 CXL 的设备,他们可以向 CPU 或 GPU 主机处理器添加内存。这意味着 CPU 和 GPU 可以以 DRAM 的速度访问 TB 级的存储空间。
虽然存储与 DRAM 的延迟实际上没有可比性(例如,分别为 80 微秒到 0.25 微秒),但仍然没有真正需要将所有内容都转移到 DRAM 中。使用 CXL,系统可以通过 CPU 中内置的现有内存层次结构从 SSD 获取所需的数据,这意味着不需要文件系统和所有伴随层,这些层可能会增加 10 到 20 微秒的延迟。
当然,文件系统不会很快消失,因为它们对于通用计算具有重要的用途。但通过 CXL,组织可以创建 SSD 存储数据池,从而以 DRAM 成本的一小部分来增强计算能力。因此,现在,组织不再局限于适合 128 GB DRAM 的数据集,而是可以拥有以 PCIe Gen6 速度运行的数百 TB NVMe SSD 存储。
CXL 的其他好处包括:
-
-
- 专为内存密集型应用程序设计的开源行业标准
- 支持异构计算并提高本地和云平台的资源利用率
- 通过跨服务器和应用程序快速、高效地共享数据来增强协作
- 允许团队在相同的内存数据集上运行并发进程
-

CXL 用例
由于它支持跨整个系统的大型内存池,因此 CXL 非常适合需要大量内存数据的工作负载。这些工作负载包括:
-
-
- 人工智能、机器学习和数据分析 – 深度学习、交互式集成开发环境 (IDE) 培训
- 在线事务处理(OLTP)和在线分析处理(OLAP)
- 媒体和娱乐 – 图形模拟、渲染和特效
- 基因研究——测序和组装分析
- 电子设计自动化 (EDA) 和计算机辅助工程 (CAE) – 建模和仿真
- 金融服务应用程序——支持决策和分析
- 高性能计算——建模和仿真
- 云 – 内核虚拟机 (KVM) 的快照、非容错工作负载的临时实例
-
超大规模企业和云服务提供商可能会倾向于 CXL,因为它具有超快的扩展和配置功能。
NVMe over Fabric (NVMe-oF)
随着时间的推移,存储区域网络 (SAN) 的传输协议已经发生了显着的发展。人们开发了不同的协议来连接基于 HDD 的 SAN,例如 iSCSI、串行连接 SCSI (SAS) 和光纤通道协议 (FCP)。这些协议为 HDD 提供了足够的性能,但对于 SSD 来说还不够。当HDD更换为SSD,HDD瓶颈被消除后,协议本身就成为了瓶颈。基于 NAND 闪存的存储需要更多的东西来帮助组织获得该技术的所有优势。
随着数据池规模越来越大,它们并不总是通过 PCIe 结构进行连接,而 PCIe 结构对大约 100 英尺的物理距离有效。除此之外,还需要其他东西。这就是 NVMe over Fabrics (NVMe-oF) 的用武之地。该协议充当消息传递层,支持主机服务器和固态存储或其他设备之间或通过扩展网络(也称为结构)之间的数据传输。
NVMe-oF 非常适合使用闪存或其他 SSD 存储的块存储。它提供低延迟和高性能,以及简单的可扩展性,并支持四种主要网络协议,即光纤通道、iWARP、InfiniBand、RDMA、RoCE(融合以太网上的 RDMA)和 TCP/IP。 NVMe-oF 比网络附加存储 (NAS) 更好,因为它的开销要少得多。如今,一旦距离对于 PCIe 来说太大,从延迟的角度来看,它已经是最好的了。
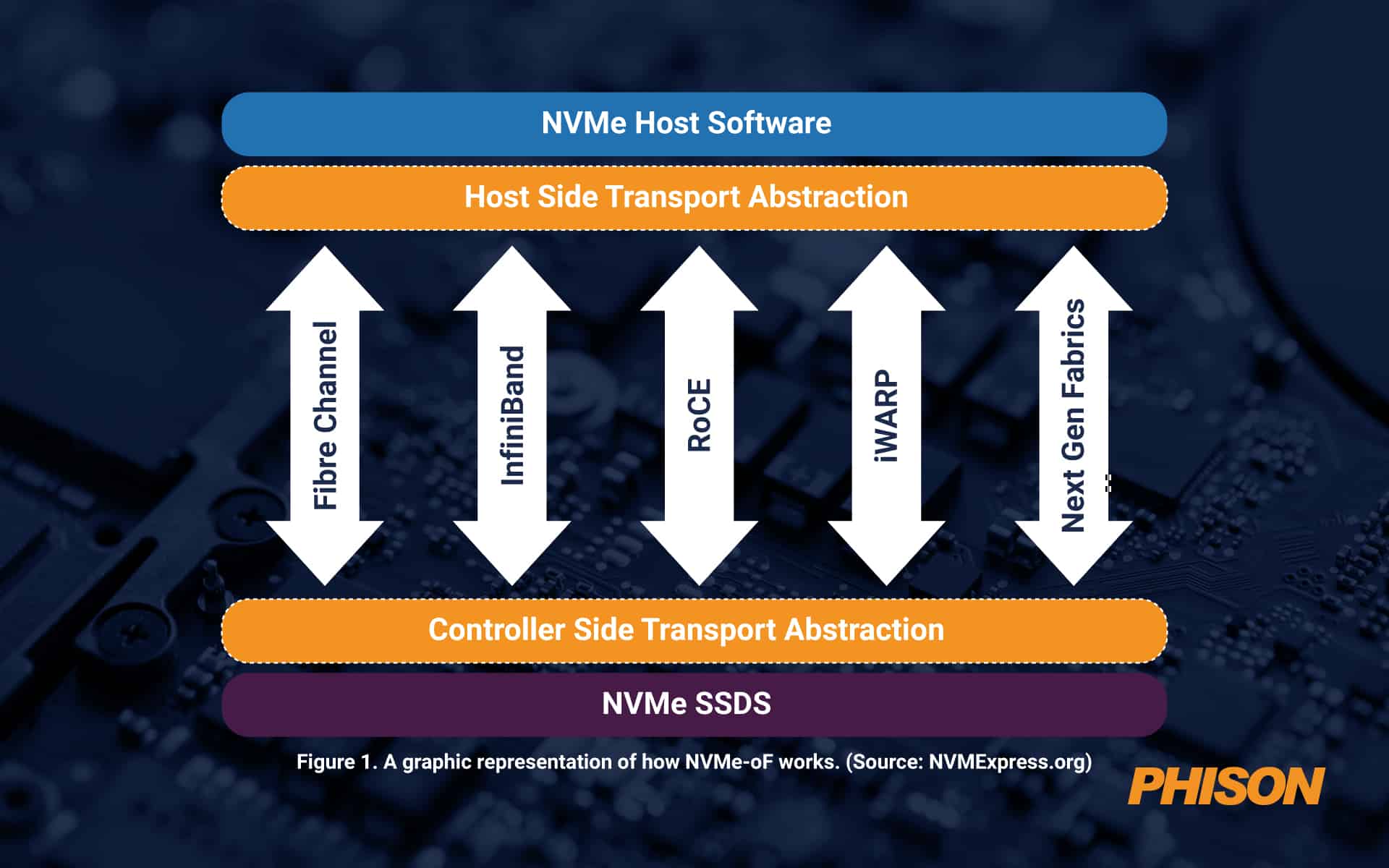
图 1. NVMe-oF 工作原理的图形表示。 (来源: NVMExpress.org)
NVMe-oF 的优势
NVMe-oF 能够创建类似于直连存储 (DAS) 的低延迟高性能存储网络。这意味着整个系统的服务器可以根据需要共享闪存设备。从本质上讲,组织可以获得基于闪存的阵列的快速性能以及共享或网络存储的优势。
使用 NVMe-oF,组织可以创建一个与服务器分离并作为单个共享池进行管理的存储系统。这意味着 IT 可以比以往更精细、更灵活地配置存储资源。
其他好处包括:
-
-
- 超低延迟
- 服务器应用程序和存储之间的连接速度更快
- 更高效的 CPU 使用率
- 更高的利用率
- 管理更轻松
- 提高整体性能
- 额外的并行请求
- 提高冗余度和弹性
-
NVMe-oF 用例
NVMe-oF 协议非常适合涉及通过网络将数据从存储移动到任何闪存介质的任何用例。如今,许多组织在高性能至关重要的情况下使用 NVMe-oF,例如人工智能或机器学习、数据分析和高性能计算。它还非常适合事务性工作负载。

群联提供尖端 SSD 以满足当今的高级需求
随着数据传输速度的提高, 群联 可以为客户提供 PCIe Gen5 SSD平台定制 在他们的应用程序中发挥最佳性能。事实上,Phison最近发布了业界首款Gen5 SSD之一, 群联E26,可为当今的大型复杂工作负载提供业界最快的速度。
此外,群联持续大力投资研发,打造符合新兴技术的 SSD 解决方案,确保其产品面向未来并准备好为未来的创新提供动力。

常见问题 (FAQ):
为什么分解基础设施对于数据中心很重要?
分解的基础设施允许记忆和 计算 独立扩展。而不是 分配 每台服务器的内存固定,资源会根据需要从公共池中提取。这种灵活性使得 超大规模者 和云提供商支持动态工作负载,如人工智能训练、模拟或实时分析,而无需过度配置。
NVMe-oF 与传统 SAN 协议相比如何?
与 SAS、iSCSI 或 纤维 渠道, 分别是 优化 对于 HDD, NVMe-oF 专为基于闪存的介质而设计。它通过网络提供近本地存储延迟,能够高效地进行远距离扩展,并支持 RoCE 和 TCP/IP 等高性能协议,使其成为以 SSD 为中心的架构的理想选择。
是什么让 Phison SSD 与下一代存储网络兼容?
Phison 的 PCIe Gen5 SSD(包括 E26 和 Pascari 系列)专为高吞吐量、低延迟和强大的耐用性而设计, CXL 的关键要求和 NVMe-oF 用例。 他们是 优化 用于 AI 工作负载、大数据传输和基于低延迟结构的存储部署。
CXL 和 NVMe-oF 的延迟优势是什么?
与 PCIe 相比,CXL 显著降低了内存访问延迟,从而使池化 SSD 存储具有 DRAM 速度的性能。 NVMe-oF 最大限度地减少网络开销,即使在较长的距离上也能提供接近 DAS 的延迟, 这使得这两种技术对于时间敏感的数据操作都至关重要。
Phison 如何确保其 SSD 解决方案的未来发展?
通过c继续大力投资研发并与 CXL 等新兴标准紧密结合 NVMe-oF, 群联 确保其固态硬盘 保持 为不断变化的工作负载做好准备。该公司设计可定制的固件和硬件堆栈,以满足各种企业性能、耐用性和集成需求。






