
ネットワークは当初からデータセンターの重要な要素でした。システムがエンタープライズ エコシステム全体でリソースをどのように接続するかによって、システムの効率と効果が大きく変わります。
過去 10 年ほどにわたって、エンタープライズ データ センターは、クラウド、エッジ コンピューティング、コンテナ化、クラウド ネイティブ コンピューティングなどの多くの技術進歩に対応して急速に進化してきました。競争力を維持するには、組織は高度に自動化され、システム全体で効率的かつ迅速にデータを移動できる、スマートで柔軟なストレージ アーキテクチャを導入する必要があります。
この記事では、急速な成長を促進する 2 つの具体的な要因を見ていきます。 データセンターストレージの進化 ネットワーキング:

コンピューティング エクスプレス リンク (CXL)
CXL は、メモリをサーバーおよびストレージ内のタスクの処理にリンクするオープン標準のキャッシュ コヒーレント インターコネクトです。これは、しばらくの間標準となっている、すでに高速な PCI Express (PCIe) インターコネクト上に構築されています。
最新の PCIe イテレーションである Gen5 では、CPU と周辺機器を最大 32 ギガ転送/秒 (GT/s) の速度で接続できる可能性があります。ただし、PCIe には、今日のデータ アクセス速度の妨げとなるいくつかの制限があります。それらの制限の 1 つは、メモリの分離されたストアをあまり効率的に管理できないことです。もう 1 つは、PCIe の遅延が高すぎて、複数のデバイス間でメモリを効率的に共有できないことです。
これを考慮してください。今日のサーバーの多く、特にハイパースケーラーのサーバーには、独自のオンボード メモリを備えたコンポーネントが含まれています。ホスト プロセッサに接続されているメイン メモリの他に、スマート NIC、GPU、ストレージ SSD が存在する場合もあります。これらのデバイスにはメモリ キャッシュが搭載されていますが、場合によっては十分に活用されていないことがよくあります。つまり、システム全体で、多くのメモリがアイドル状態になっているということです。未使用のメモリを何千台ものサーバーで増やすと、その量は膨大になります。通常、これらのキャッシュは、接続するツールがない限り対話できません。
CXL はこれらの制限を克服します。ストレージ クラス メモリが多数の処理ノードを適切に処理できないという問題に部分的に対処するために開発された CXL は、PCIe の物理接続層と電気構成を利用しますが、メモリからデータにアクセスする際の遅延が大幅に低くなります。ホスト サーバーと他のデバイスの間にキャッシュの一貫性が提供されるため、システム全体のメモリが単一のアクセス可能なプールとして扱われます。これらのメモリ プールは容量を大幅に増加させることができ、CPU および GPU プロセッサ、計算ストレージ、インテリジェント ネットワーク インターフェイス カード (NIC) に直接リンクできます。
CXL 互換システムの立ち上げが始まったばかりで、このテクノロジーはプラットフォームとデータセンターの設計と運営の方法を変革する可能性を秘めています。業界は、各ノードが独自のメモリと処理を持つという概念から徐々に移行し、任意の数の GPU、CPU、およびプロセッサを含むエコシステム全体にサービスを提供する、大きな単一のメモリ プールからワークロードにリソースを割り当てる分散インフラストラクチャを支持します。計算ストレージ。これにより、組織は大容量のメモリを備えたデータセンターを構築できるようになります。

CXL の利点
CXL を使用すると、組織はストレージ、コンピューティング、メモリ、ストレージ クラス メモリ間の独自の相互接続に制限されなくなり、複数のプロセッサが以前よりも大きなメモリ プールを共有できるようになります。
CXL を使用すると、組織は DRAM を超える容量と帯域幅を実現できます。 CXL に接続されたデバイスを使用して、CPU または GPU ホスト プロセッサにメモリを追加できます。これは、CPU と GPU が DRAM 速度でテラバイトのストレージにアクセスできることを意味します。
ストレージと DRAM のレイテンシは実際には比較できませんが (たとえば、それぞれ 80 マイクロ秒と 0.25 マイクロ秒)、すべてを DRAM に移動する実際の必要性はありません。 CXL を使用すると、システムは CPU に組み込まれた既存のメモリ階層を介して SSD から必要なデータをフェッチできます。つまり、10 ~ 20 マイクロ秒の遅延が追加される可能性があるファイル システムや付随するすべてのレイヤーが必要ありません。
もちろん、ファイル システムは一般的なコンピューティングにとって貴重な目的を果たしているため、すぐになくなることはありません。しかし、CXL を使用すると、組織は DRAM の数分の 1 のコストでコンピューティング機能を強化する SSD ストレージ データのプールを作成できます。そのため、組織は 128 GB の DRAM に収まるデータセットに限定されるのではなく、PCIe Gen6 速度で実行される数百 TB の NVMe SSD ストレージを保有できるようになりました。
CXL のその他の利点は次のとおりです。
-
-
- メモリを大量に使用するアプリケーション向けに設計されたオープンソースの業界標準
- ヘテロジニアス コンピューティングを可能にし、オンプレミスとクラウド プラットフォーム全体でのリソース使用率を向上させます。
- サーバーとアプリケーション間でのデータの高速かつ効率的な共有を可能にすることでコラボレーションを強化します。
- チームが同じメモリ内データセット上で同時プロセスを実行できるようにします
-

CXL の使用例
CXL はシステム全体にわたる大規模なメモリ プールを可能にするため、大量のメモリ内データを必要とするワークロードに最適です。これらのワークロードには次のものが含まれます。
-
-
- AI、機械学習、データ分析 – ディープラーニング、インタラクティブな統合開発環境 (IDE) のトレーニング
- オンライン トランザクション処理 (OLTP) およびオンライン分析処理 (OLAP)
- メディアとエンターテイメント - グラフィック シミュレーション、レンダリング、特殊効果
- 遺伝子研究 – 配列決定およびアセンブリ分析
- 電子設計自動化 (EDA) およびコンピュータ支援エンジニアリング (CAE) – モデリングとシミュレーション
- 金融サービス アプリケーション – 意思決定と分析のサポート
- ハイパフォーマンス コンピューティング - モデリングとシミュレーション
- クラウド – カーネル仮想マシン (KVM) のスナップショット、フォールト トレラントではないワークロードのアドホック インスタンス
-
ハイパースケーラーやクラウド サービス プロバイダーは、その超高速スケーリングとプロビジョニング機能により、CXL に引き寄せられる可能性があります。
NVMe オーバー ファブリック (NVMe-oF)
ストレージ エリア ネットワーク (SAN) のトランスポート プロトコルは、時間の経過とともに大幅に進化しました。 HDD ベースの SAN に接続するために、iSCSI、シリアル アタッチド SCSI (SAS)、ファイバー チャネル プロトコル (FCP) などのさまざまなプロトコルが開発されました。これらのプロトコルは HDD には十分なパフォーマンスを提供しましたが、SSD には十分ではありませんでした。 HDD を SSD に置き換えることで HDD のボトルネックが解消された後は、プロトコル自体がボトルネックになりました。 NAND フラッシュベースのストレージには、組織がテクノロジーのメリットを最大限に享受できるよう、さらに何かが必要でした。
データのプールのサイズが大きくなるにつれて、物理的距離が約 100 フィートの場合でも有効な PCIe ファブリックを介して接続できるとは限りません。それを超えて、何か別のことが必要です。そこで、NVMe over Fabrics (NVMe-oF) が登場します。このプロトコルは、ホスト サーバーとソリッド ステート ストレージまたはその他のデバイス間、またはファブリックとも呼ばれる拡張ネットワーク上でのデータ転送を可能にするメッセージング層として機能します。
NVMe-oF は、フラッシュまたはその他の SSD ストレージを使用するブロック ストレージに最適です。これは、高いパフォーマンスを備えた低遅延を実現するだけでなく、シンプルなスケーラビリティと、ファイバー チャネル、iWARP、InfiniBand、RDMA、RoCE (RDMA over Converged Ethernet)、TCP/IP という 4 つの主要なネットワーク プロトコルのサポートを実現します。 NVMe-oF はオーバーヘッドがはるかに少ないため、ネットワーク接続ストレージ (NAS) よりも優れています。現在では、距離が PCIe に対して大きくなりすぎると、遅延の観点からはこれが可能な限り良好になります。
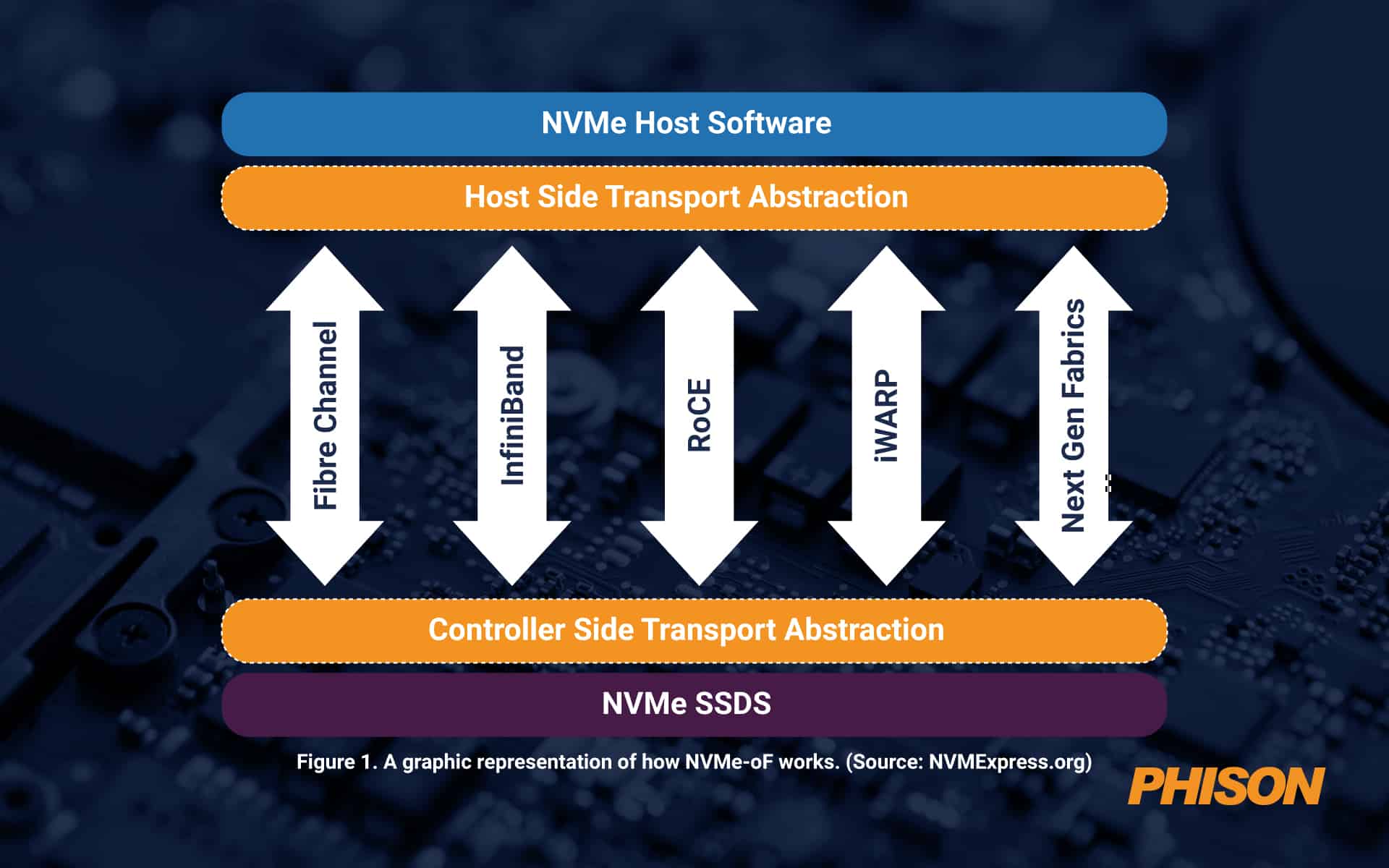
図 1. NVMe-oF の仕組みを図で表したもの。 (ソース: NVMExpress.org)
NVMe-oF の利点
NVMe-oF は、ダイレクト アタッチド ストレージ (DAS) と同様の、低遅延の高性能ストレージ ネットワークを作成する機能を提供します。つまり、システム全体のサーバーが必要に応じてフラッシュ デバイスを共有できるということです。基本的に、組織は共有ストレージまたはネットワーク ストレージの利点と組み合わせて、フラッシュ ベースのアレイの高速パフォーマンスを得ることができます。
NVMe-oF を使用すると、組織はサーバーから分離され、単一の共有プールとして管理されるストレージ システムを作成できます。つまり、IT 部門はストレージ リソースをこれまでよりもきめ細かく柔軟にプロビジョニングできるようになります。
その他の利点は次のとおりです。
-
-
- 超低遅延
- サーバー アプリケーションとストレージ間の接続の高速化
- CPU 使用率の向上
- 稼働率の向上
- 管理が容易になる
- 全体的なパフォーマンスの向上
- 追加の並列リクエスト
- 冗長性と復元力の向上
-
NVMe-oF の使用例
NVMe-oF プロトコルは、ネットワーク経由でストレージからフラッシュ メディアにデータを移動するあらゆるユースケースに最適です。現在、多くの組織が、AI や機械学習、データ分析、ハイパフォーマンス コンピューティングなど、高いパフォーマンスが重要な場合に NVMe-oF を使用しています。トランザクション ワークロードにも適しています。

Phison は今日の高度なニーズに応える最先端の SSD を提供します
データ転送速度が速くなると、 ファイソン 顧客に提供できるのは カスタマイズされた PCIe Gen5 SSD プラットフォーム アプリケーションで最適なパフォーマンスを発揮します。実際、Phison は最近、業界初の Gen5 SSD の 1 つをリリースしました。 フィソンE26は、今日の大規模で複雑なワークロードに対して業界最速の速度を実現します。
さらに、Phison は、新興テクノロジーに適合する SSD ソリューションを作成するための研究開発に継続的に多額の投資を行っており、その製品が将来性があり、明日のイノベーションを推進できるようになっています。

よくある質問(FAQ):
データセンターにとって分散型インフラストラクチャが重要なのはなぜですか?
分散型インフラストラクチャにより、メモリと 計算する 独立してスケールする。 割り当てる サーバーごとに固定メモリがあり、必要に応じて共通プールからリソースが引き出されます。この柔軟性により、 ハイパースケーラー クラウド プロバイダーと連携して、過剰なプロビジョニングなしで AI トレーニング、シミュレーション、リアルタイム分析などの動的なワークロードをサポートします。
NVMe-oF は従来の SAN プロトコルと比べてどうですか?
SAS、iSCSI、または ファイバ チャネル, これらは 最適化された HDD用, NVMe-oF フラッシュベースのメディア向けに設計されています。ネットワーク経由でローカルに近いストレージレイテンシを提供し、距離に応じて効率的に拡張可能で、RoCEやTCP/IPなどの高性能プロトコルをサポートしているため、SSD中心のアーキテクチャに最適です。
Phison SSD が次世代ストレージ ネットワークと互換性を持つ理由は何ですか?
E26およびPascariシリーズを含むPhisonのPCIe Gen5 SSDは、高スループット、低レイテンシ、堅牢な耐久性を実現するように設計されています。, CXLの主な要件と NVMe-oF ユースケース。 彼らは 最適化された AI ワークロード、大規模データ転送、低レイテンシのファブリックベースのストレージ展開に最適です。
CXL と NVMe-oF のレイテンシの利点は何ですか?
CXL は、PCIe と比較してメモリ アクセスのレイテンシを大幅に削減し、プールされた SSD ストレージで DRAM 速度のパフォーマンスを実現します。 NVMe-oF ネットワークのオーバーヘッドを最小限に抑え、長距離でもDASに近いレイテンシを実現, どちらの技術も、時間に敏感なデータ操作にとって非常に重要になります。
Phison はどのようにして SSD ソリューションを将来にわたって保証するのでしょうか?
cを通じて継続研究開発への多額の投資とCXLや NVMe-oF, ファイソン SSDの保証 残る 進化するワークロードに対応します。当社は、企業の多様なパフォーマンス、耐久性、統合ニーズを満たす、カスタマイズ可能なファームウェアとハードウェアスタックを設計しています。






