
SC25에서 Phison은 자사의 aiDAPTIV+ 하드웨어 및 소프트웨어 솔루션의 잠재력을 선보이며, 두 개의 GPU와 192GB의 VRAM을 탑재한 단일 서버에서 4,050억 개의 파라미터를 가진 Llama 3.1 모델을 정밀 학습시키는 시연을 진행했습니다. 일반적으로 이 작업에는 7TB가 넘는 VRAM 풀과 여러 대의 NVIDIA 서버가 필요하며, 이는 대규모의 고비용 시스템 구축을 의미합니다. 하지만 Phison은 aiDAPTIV+의 강력한 성능 덕분에 약 145만 달러(TP4T50,000) 정도의 비용으로 이 모든 작업을 단일 시스템에서 수행할 수 있었습니다.
이 기술의 핵심은 LLM 계산에 필요한 가중치와 값을 저장하는 데 사용된 8TB aiDAPTIVCache SSD였습니다. aiDAPTIV+는 복잡한 미세 조정 작업을 VRAM에 모두 담으려는 대신 더 작고 관리하기 쉬운 단위로 나누어 처리합니다. 그 결과, 다양한 조직에서 더욱 강력한 AI 모델을 활용할 수 있게 되었습니다.
aiDAPTIV+가 LLM 미세 조정 학습에 제공하는 다재다능함의 한 예로, 이 시스템은 일반적으로 8개의 H100 GPU가 탑재된 NVIDIA HGX H100 서버 12대가 필요한 작업을 완료했습니다. 이러한 서버는 훨씬 더 많은 공간과 전력을 필요로 하며, 비용 또한 Phison 부스 내에서 동일한 작업을 수행한 aiDAPTIV+ 서버보다 훨씬 높습니다.

aiDAPTIV+란 무엇인가요?
aiDAPTIV+는 AI 모델의 미세 조정 학습을 위한 메모리 공간을 확장하고 추론 워크로드의 첫 번째 토큰 획득 시간(TTFT)을 가속화하도록 설계된 하드웨어 및 소프트웨어 솔루션입니다. 특수 aiDAPTIVCache SSD는 압축 해제된 LLM의 텐서 가중치와 학습용 벡터를 저장하는 임시 영역 역할을 합니다. aiDAPTIVLink 미들웨어는 메모리 할당을 관리하고 사용 가능한 리소스를 가장 효율적으로 활용하는 방법을 결정하여 필요에 따라 aiDAPTIVCache SSD에서 VRAM 또는 DRAM으로 데이터를 이동합니다.
aiDAPTIVCache SSD는 이러한 작업을 위해 특별히 설계되었으며, 하루 100회 쓰기(DWPD)라는 매우 높은 내구성을 자랑합니다. 이 SSD는 SLC NAND를 사용하여 이러한 수준의 내구성과 지속적인 고속 처리량을 구현합니다. aiDAPTIVCache SSD에는 집중적인 사용 환경에서 하루 300TB 이상을 기록할 수 있는데, 이는 일반 SSD가 두 달도 채 안 되어 고장나는 것과 같은 수준입니다. aiDAPTIVCache 드라이브는 이러한 까다로운 환경에서도 5년간 지속적인 사용에도 견딜 수 있도록 설계되었습니다.
순수 GPU VRAM을 사용하는 경우와 비교했을 때 미세 조정 학습 과정 완료 시간은 증가하지만, 성능 저하의 대부분은 GPU 개수와 사용 가능한 컴퓨팅 자원이 부족하기 때문입니다. aiDAPTIVCache SSD는 심각한 병목 현상을 일으키지 않을 만큼 충분히 빠르므로, 유사한 수의 GPU를 사용하는 순수 GPU 기반 학습보다 학습 시간이 약 5% 정도 더 오래 걸립니다. 하지만 aiDAPTIV+를 사용하면 기존 방식으로는 데이터셋 미세 조정이 불가능했던 GPU에서도 훨씬 더 큰 모델을 사용할 수 있기 때문에 직접적인 비교는 큰 의미가 없습니다.

aiDAPTIV+ AITPC에서 두 개의 RTX 4000 Ada GPU로 Pro Suite를 실행 중입니다.
Llama 3.1 405B aiDAPTIV+ 서버 교육 세부 정보
SC25에서 Phison이 사용한 서버는 Llama 3.1 405B 모델 학습을 가능하게 하는 다음과 같은 하드웨어를 갖추고 있었습니다.
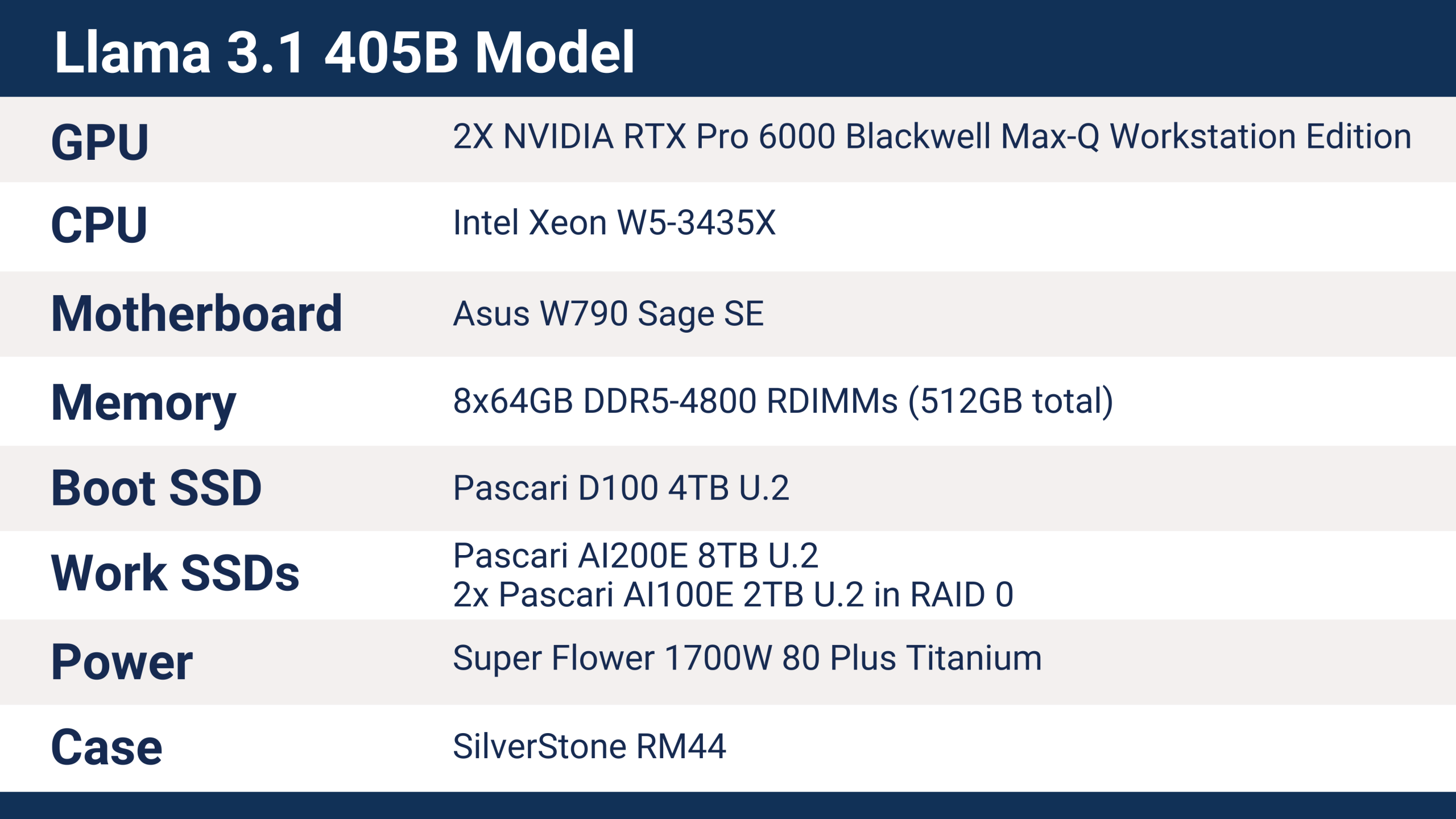
aiDAPTIV+는 Intel 및 AMD CPU, ARM 프로세서, 다양한 마더보드 및 칩셋, 그리고 폭넓은 메모리 용량을 포함한 다양한 최신 플랫폼을 지원합니다. CPU는 aiDAPTIV+ 실행에 있어 주요 요소는 아니지만, 워크스테이션 및 서버 플랫폼은 훨씬 더 다양한 연결 옵션을 제공합니다. 클라이언트 솔루션도 작동하지만, 지원하는 PCIe 레인 수가 적어 스토리지 장치와 GPU의 성능에 직접적인 영향을 미칩니다. 특히 여러 개의 GPU와 여러 개의 SSD를 사용할 때 이러한 영향이 두드러집니다.
Phison SC25 서버는 인텔의 Sapphire Rapids 제품군에 속하는 Xeon W5-3435X 프로세서를 사용하며, 총 112개의 PCI Express 5.0 레인을 제공합니다. 각 RTX Pro 6000 GPU는 x16 PCIe Gen5 슬롯을 사용하고, SSD는 U.2 x4 연결을 사용합니다. 이 서버 구성은 기본 구성에 가깝지만, 추가 aiDAPTIVCache SSD 및 GPU를 통해 성능을 향상시킬 수 있는 충분한 확장 옵션이 있습니다.
SC25에서 사용된 aiDAPTIVCache SSD는 8TB U.2 모델로, 4050억 개의 파라미터를 가진 모델 학습에 필요한 용량입니다. LLM의 미세 조정 학습에는 파라미터 수의 약 20배에 달하는 메모리 용량이 필요합니다. 이 경우 4050억 개의 파라미터는 약 8TB의 메모리에 해당합니다. 일반적으로 이러한 메모리는 VRAM 또는 시스템 RAM을 사용하는데, 이 두 가지 모두 대량으로 구매할 경우 매우 고가입니다. aiDAPTIV+는 8TB의 NAND 플래시 스토리지를 추가하여 사용 가능한 메모리 용량을 확장합니다.
기존 방식대로 모든 데이터를 VRAM에 저장하는 방식으로 405B 모델을 학습시키려면 최신 NVIDIA B300 Ultra 가속기 약 26개가 필요합니다. 이는 각각 8개의 GPU가 탑재된 서버 4대가 필요하다는 의미이며, 각 GPU의 가격은 aiDAPTIV+ 서버 전체 가격과 맞먹습니다. 또는, NVIDIA B200 GPU 약 40개를 서버 5대에, H200 GPU 약 53개를 서버 7대에, 또는 HGX H100 서버 93대에 H100 가속기 약 93개를 사용할 수도 있습니다. 또한 모든 네트워킹 및 상호 연결 하드웨어가 필요하며, 총 전력 소비량은 40kW에서 80kW에 달합니다. 반면 aiDAPTIV+ 서버는 약 1kW의 전력만 소비하며 추가 인프라가 필요하지 않습니다.
aiDAPTIV+ 훈련 결과 및 성능
Phison은 SC25 데모를 위해 Llama 3.1 405B LLM을 미세 조정하기 위해 Hugging Face에서 찾은 Dolly 창작 글쓰기 벤치마크를 사용했습니다. 데이터 세트에 따라 학습에 필요한 시간이 달라지지만, 확장성은 다양한 하드웨어 솔루션에서 유사하게 유지됩니다.
기본 Llama-3.1-405B-Instruct 모델은 Safetensors 형식을 사용하며 크기가 2TB입니다. 학습 과정의 첫 번째 단계는 LLM 텐서를 메모리(이 경우에는 aiDAPTIVCache SSD)로 압축 해제하는 것입니다. 이 과정에서 5TB가 넘는 데이터가 생성되며, 생성하는 데 약 30분이 소요됩니다. 학습 과정 중 최대 7TB 이상의 메모리가 사용될 수 있습니다.
Dolly 데이터셋은 77만 1천 개의 문자와 672개의 질문/답변 쌍으로 구성되어 있으며, aiDAPTIV+ 서버는 에포크당 25시간 50분의 속도로 미세 조정 학습을 완료했습니다. 전체 과정은 2에포크의 학습 실행으로 이틀 4시간 만에 완료되었습니다.
SC25에서 aiDAPTIV+ 서버가 가동된 4일 동안, aiDAPTIV+는 aiDAPTIVCache SSD에 수백 테라바이트의 데이터를 기록했습니다. 일반적인 엔터프라이즈급 SSD는 1 DWPD(데이터 쓰기 용량) 등급으로, 이 정도의 쓰기 작업량이라면 몇 주 만에 플래시 메모리가 마모됩니다. 용량이 작은 드라이브는 마모 기간이 더 짧습니다. 하지만 Pascari aiDAPTIVCache SSD는 100 DWPD의 내구성 등급을 갖추고 있어, 이러한 작업 부하를 5년 동안 24시간 365일 가동해도 문제없이 처리할 수 있도록 설계되었습니다.

Llama 405B의 미세 조정 학습을 위해 Pascari AI200E 8TB U.2 SSD를 사용했습니다.
aiDAPTIV+로 더 많은 것을 시작하세요
aiDAPTIV+는 미세 조정 학습에 사용할 수 있는 메모리 용량을 확장하는 중요한 경로를 제공하며, 전 세계적인 DRAM 부족으로 메모리 가격이 급등하는 상황에서 훨씬 저렴한 비용으로 이를 구현할 수 있습니다. 이를 통해 막대한 재정적 투자, 데이터 센터, 또는 대량의 전력 소비 없이 온프레미스 하드웨어를 사용하여 모든 비즈니스 수준에서 AI를 활용할 수 있는 잠재력이 열립니다. aiDAPTIV+는 연구 및 교육 기관에서도 고가의 클라우드 계약이나 데이터 주권 문제 없이 대규모 모델을 실험할 수 있도록 지원합니다.
Phison의 SC25 데모는 대규모 데이터 센터와 값비싼 인프라 없이도 가장 큰 규모의 AI 모델을 다룰 수 있음을 입증했습니다. aiDAPTIV+는 특수 설계된 aiDAPTIVCache SSD와 지능형 메모리 오케스트레이션을 결합하여 하이퍼스케일러에서만 가능했던 모델 미세 조정 작업을 실용적이고 경제적인 방식으로 수행할 수 있도록 지원합니다. 더 큰 규모의 모델을 활용하고 진정한 온프레미스 AI 독립성을 확보하고자 하는 기업에게 aiDAPTIV+는 가능성의 한계를 뛰어넘는 획기적인 변화를 가져다줄 것입니다.
Phison을 방문하세요 aiDAPTIV+가 AI 워크플로우를 어떻게 혁신할 수 있는지 살펴보고 해당 기술이 실제로 어떻게 작동하는지 확인해 보세요.






