
在SC25大會上,群聯電子展示了其aiDAPTIV+軟硬體解決方案的強大潛力,在一台配備兩塊GPU和192GB顯存的伺服器上,成功完成了Llama 3.1 4050億參數模型的精細化訓練。通常情況下,這項任務需要超過7TB的顯存池和多台NVIDIA伺服器——這是一套規模龐大且成本高昂的系統。而得益於aiDAPTIV+的強大性能,所有這些工作都在一台成本約為1萬億至4萬億日元的系統上完成。.
實現這一目標的關鍵在於一塊 8TB 的 aiDAPTIVCache SSD,它用於儲存 LLM 的運算權重和值。 aiDAPTIV+ 將複雜的微調任務分解成更小、更易於管理的部分,而不是試圖將所有內容都塞進顯存中。最終,它使更多組織能夠更輕鬆地使用更強大的 AI 模型。.
為了展示aiDAPTIV+在LLM微調訓練方面的多功能性,該系統完成了一項通常需要十二台NVIDIA HGX H100伺服器(每台伺服器配備八個H100 GPU)才能完成的任務。這些伺服器需要更大的空間和電力,成本也遠高於在群聯電子展位上完成相同任務的aiDAPTIV+伺服器。.

aiDAPTIV+是什麼?
aiDAPTIV+ 是一款軟硬體結合的解決方案,旨在擴展記憶體空間,用於微調 AI 模型的訓練,並加速推理工作負載的首次標記時間 (TTFT)。專用的 aiDAPTIVCache SSD 用作解包後的 LLM 張量權重和向量的暫存區,用於訓練。 aiDAPTIVLink 中間件負責管理記憶體分配,並確定如何最佳利用可用資源,根據需要將資料從 aiDAPTIVCache SSD 移入 VRAM 或 DRAM。.
aiDAPTIVCache SSD專為此類任務而設計,具有高達100 DWPD(每日寫入量)的超高耐久性。這些SSD採用SLC NAND快閃記憶體,實現如此高的耐久性和持續高速的吞吐量。在重度使用情況下,aiDAPTIVCache SSD每天可寫入超過300TB的數據,而普通SSD在不到兩個月的時間內就會損壞。 aiDAPTIVCache SSD經測試可應付這種嚴苛的使用場景長達五年之久。.
雖然與僅使用 GPU 顯存相比,完成微調訓練過程所需的時間有所增加,但效能下降主要源自於可用 GPU 數量和運算能力的減少。 aiDAPTIVCache SSD 的速度足夠快,不會造成嚴重的瓶頸,因此訓練時間比在類似數量的 GPU 上進行的純 GPU 訓練大約長 5%。然而,直接比較意義不大,因為 aiDAPTIV+ 允許在原本無法進行資料集微調的 GPU 上運行規模更大的模型。.

aiDAPTIV+ AITPC 在兩塊 RTX 4000 Ada GPU 上執行 Pro Suite。.
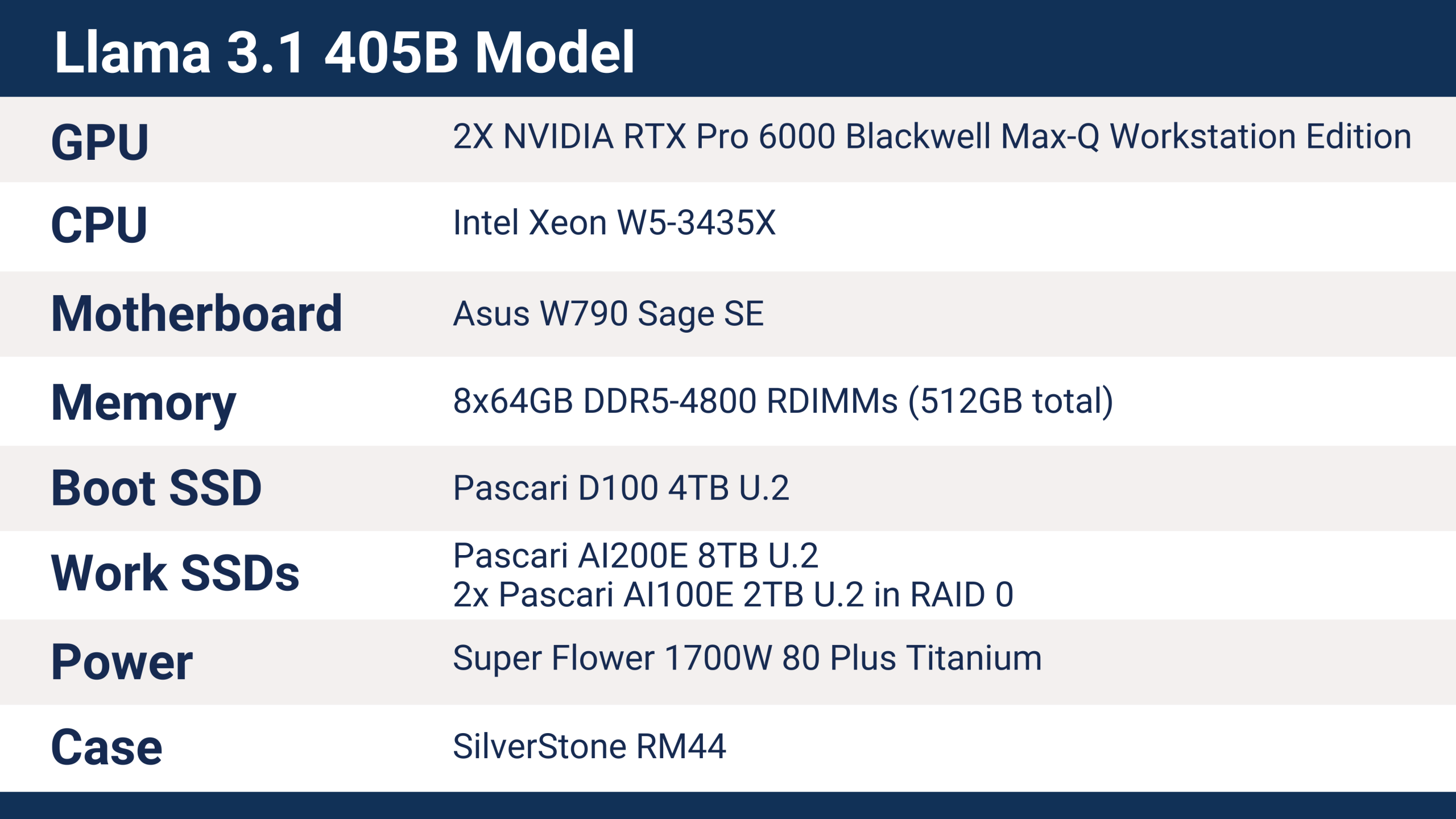
Llama 3.1 405B aiDAPTIV+ 伺服器培訓詳情
Phison 在 SC25 上使用的伺服器配備了以下硬件,可對 Llama 3.1 405B 模型進行訓練。.
aiDAPTIV+ 支援多種現代平台,包括 Intel 和 AMD CPU、ARM 處理器、各種主機板和晶片組,以及各種記憶體容量。 CPU 並非執行 aiDAPTIV+ 的主要因素,但工作站和伺服器平台可提供更豐富的連線選項。客戶端解決方案雖然也能運行,但支援的 PCIe 通道數量較少,這會直接影響儲存裝置和 GPU 的效能——尤其是在使用多個 GPU 和多個 SSD 時。.
Phison SC25 伺服器採用藍寶石 Rapids 系列的英特爾至強 W5-3435X 處理器,提供 112 條 PCI Express 5.0 通道。每塊 RTX Pro 6000 GPU 均使用一個 x16 PCIe Gen5 插槽,SSD 則使用 U.2 x4 介面。此伺服器的配置屬於基礎配置,預留了充足的擴充空間,例如可新增額外的 aiDAPTIVCache SSD 和 GPU 以提升效能。.
在 SC25 大會上,aiDAPTIVCache SSD 使用的是 8TB U.2 型號,這是處理 4,050 億參數模型訓練所需的容量。 LLM 模型的微調訓練所需的記憶體容量約為參數數量的 20 倍。在這種情況下,4050 億參數相當於大約 8TB 的記憶體。這些記憶體通常是顯存(VRAM),在某些情況下也可能是系統記憶體(RAM),但如此大容量的顯存和系統記憶體都非常昂貴。 aiDAPTIV+ 透過 8TB 的 NAND 快閃記憶體來擴充可用記憶體。.
如果採用傳統的將所有資料保存在顯存(VRAM)中的方法,而不是使用 aiDAPTIV+,訓練一個 405 億位元組的模型大約需要 26 個最新的 NVIDIA B300 Ultra 加速器,這意味著需要四台伺服器,每台伺服器配備八個 GPU——而每個 GPU 的成本就相當於整個 aiDAPTIV+ 伺服器。另一種方案是使用約 40 個 NVIDIA B200 GPU(分佈在五台伺服器上)、53 個 H200 GPU(運行在七台伺服器上)或 93 個 H100 加速器(安裝在十二台 HGX H100 伺服器中)。此外,還需要所有網路和互連硬件,總功耗在 40 kW 到 80 kW 之間。而 aiDAPTIV+ 伺服器僅消耗約 1 kW 的功率,且無需任何額外的基礎設施。.
aiDAPTIV+ 訓練結果與表現
Phison 使用 Hugging Face 網站上的 Dolly 創意寫作基準測試資料集,對 Llama 3.1 405B LLM 模型進行了微調,以用於 SC25 演示。不同的資料集會影響訓練所需的時間,但不同硬體解決方案的擴展性仍然相似。.
基礎的 Llama-3.1-405B-Instruct 模型大小為 2 TB,採用 Safetensors 格式。訓練過程的第一步是將 LLM 張量解包到記憶體中-在本例中是解包到 aiDAPTIVCache SSD 中。這會產生超過 5 TB 的數據,產生時間約為 30 分鐘,訓練過程中記憶體使用峰值超過 7 TB。.
Dolly 資料集包含 77.1 萬個字元和 672 個問答對,aiDAPTIV+ 伺服器以每輪 25 小時 50 分鐘的速度完成了微調訓練。整個過程耗時兩天四小時,訓練週期為兩輪。.
在 aiDAPTIV+ 伺服器以 SC25 頻率運行的四天裡,aiDAPTIV+ 向 aiDAPTIVCache SSD 寫入了數百 TB 的資料。對於額定寫入量為 1 DWPD 的典型企業級 SSD 而言,這種寫入量會在幾週內耗盡快閃記憶體——容量較小的硬碟損耗速度會更快。 Pascari aiDAPTIVCache SSD 的耐久性評級高達 100 DWPD,專為應對此類工作負載而設計,可 24/7/365 全天候運行長達五年。.

Pascari AI200E 8TB U.2 SSD 用於 Llama 405B 的微調訓練。.
使用 aiDAPTIV+ 開始做更多事情
aiDAPTIV+ 為擴展用於微調訓練的可用記憶體提供了一條重要途徑。鑑於全球 DRAM 短缺導致記憶體價格飆升,aiDAPTIV+ 的成本僅為傳統 DRAM 的一小部分。它為企業在各個層面利用人工智慧開闢了新的途徑,用戶可以使用本地硬件,無需巨額資金投入、數據中心或大量電力。 aiDAPTIV+ 也適用於科研和教育機構,使用戶能夠在無需支付昂貴的雲端服務費用或擔心資料主權問題的情況下,對更大規模的模型進行實驗。.
Phison 在 SC25 大會上的展示證明,無需龐大的資料中心和昂貴的基礎設施即可運行最大型的 AI 模型。 aiDAPTIV+ 將專用的 aiDAPTIVCache SSD 與智慧型記憶體編排結合,為以往只有超大規模資料中心才能實現的模型微調提供了一條切實可行且經濟實惠的途徑。對於希望解鎖更大型模型並真正實現本地 AI 獨立性的企業而言,aiDAPTIV+ 代表 AI 領域的重大變革。.
訪問群組 探索 aiDAPTIV+ 如何改變您的 AI 工作流程,並了解技術的實際應用。.






