
在SC25大会上,群联电子展示了其aiDAPTIV+软硬件解决方案的强大潜力,在一台配备两块GPU和192GB显存的服务器上,成功完成了Llama 3.1 4050亿参数模型的精细化训练。通常情况下,这项任务需要超过7TB的显存池和多台NVIDIA服务器——这是一套规模庞大且成本高昂的系统。而得益于aiDAPTIV+的强大性能,所有这些工作都在一台成本约为1万亿至4万亿日元的系统上完成。.
实现这一目标的关键在于一块 8TB 的 aiDAPTIVCache SSD,它用于存储 LLM 的计算权重和值。aiDAPTIV+ 将复杂的微调任务分解成更小、更易于管理的部分,而不是试图将所有内容都塞进显存中。最终,它使更多组织能够更轻松地使用更强大的 AI 模型。.
为了展示aiDAPTIV+在LLM微调训练方面的多功能性,该系统完成了一项通常需要十二台NVIDIA HGX H100服务器(每台服务器配备八个H100 GPU)才能完成的任务。这些服务器需要更大的空间和电力,成本也远高于在群联电子展位上完成相同任务的aiDAPTIV+服务器。.

aiDAPTIV+是什么?
aiDAPTIV+ 是一款软硬件结合的解决方案,旨在扩展内存空间,用于微调 AI 模型的训练,并加速推理工作负载的首次标记时间 (TTFT)。专用的 aiDAPTIVCache SSD 用作解包后的 LLM 张量权重和向量的暂存区,用于训练。aiDAPTIVLink 中间件负责管理内存分配,并确定如何最佳利用可用资源,根据需要将数据从 aiDAPTIVCache SSD 移入 VRAM 或 DRAM。.
aiDAPTIVCache SSD专为此类任务而设计,拥有高达100 DWPD(每日写入量)的超高耐久性。这些SSD采用SLC NAND闪存,实现了如此高的耐久性和持续高速的吞吐量。在重度使用情况下,aiDAPTIVCache SSD每天可写入超过300TB的数据,而普通SSD在不到两个月的时间内就会损坏。aiDAPTIVCache SSD经测试可应对这种严苛的使用场景长达五年之久。.
虽然与仅使用 GPU 显存相比,完成微调训练过程所需的时间有所增加,但性能下降主要源于可用 GPU 数量和计算能力的减少。aiDAPTIVCache SSD 的速度足够快,不会造成严重的瓶颈,因此训练时间比在类似数量的 GPU 上进行的纯 GPU 训练大约长 5%。然而,直接比较意义不大,因为 aiDAPTIV+ 允许在原本无法进行数据集微调的 GPU 上运行规模更大的模型。.

aiDAPTIV+ AITPC 在两块 RTX 4000 Ada GPU 上运行 Pro Suite。.
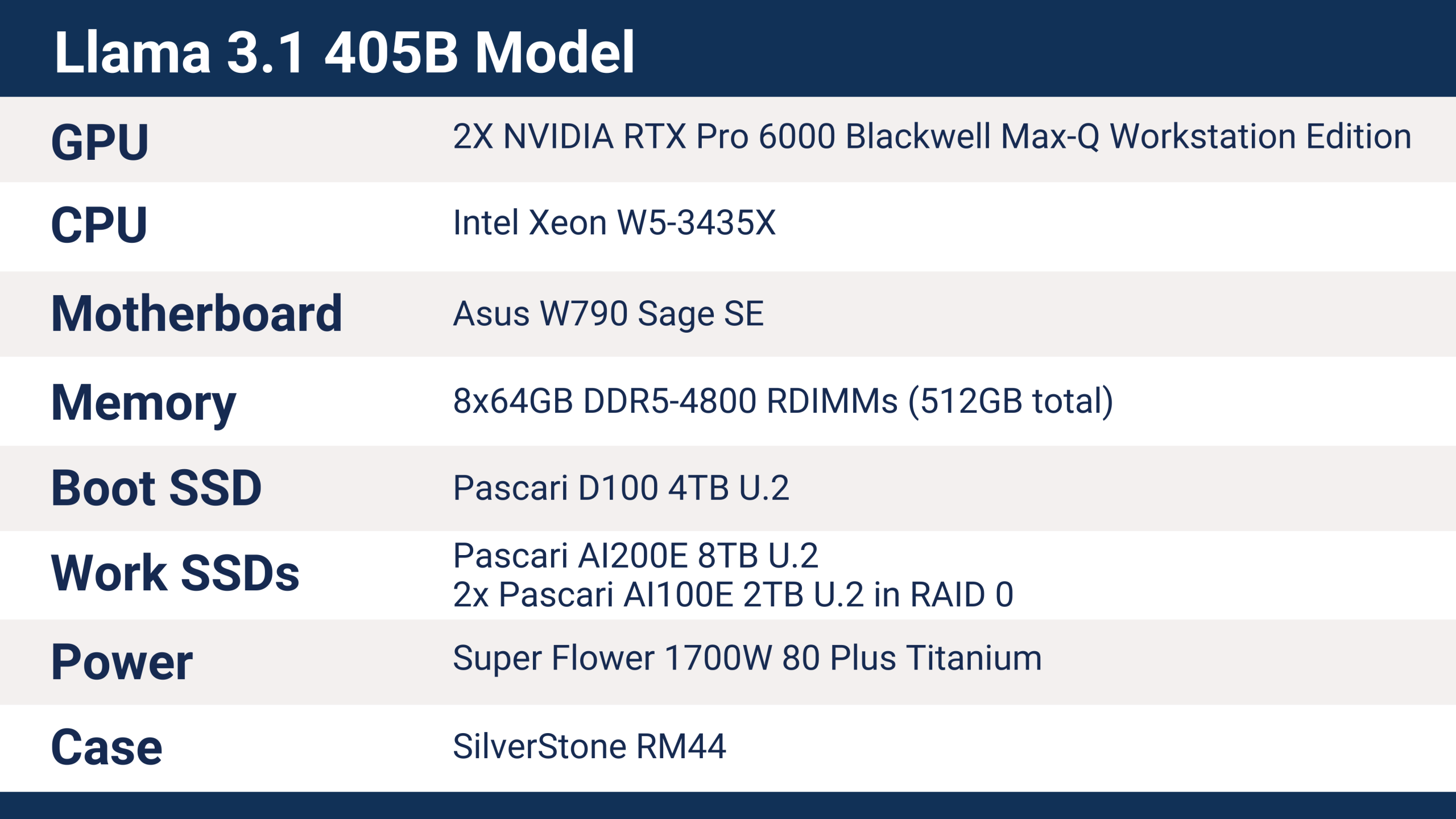
Llama 3.1 405B aiDAPTIV+ 服务器培训详情
Phison 在 SC25 上使用的服务器配备了以下硬件,可以对 Llama 3.1 405B 模型进行训练。.
aiDAPTIV+ 支持多种现代平台,包括 Intel 和 AMD CPU、ARM 处理器、各种主板和芯片组,以及各种内存容量。CPU 并非运行 aiDAPTIV+ 的主要因素,但工作站和服务器平台可提供更丰富的连接选项。客户端解决方案虽然也能运行,但支持的 PCIe 通道数量较少,这会直接影响存储设备和 GPU 的性能——尤其是在使用多个 GPU 和多个 SSD 时。.
Phison SC25 服务器采用蓝宝石 Rapids 系列的英特尔至强 W5-3435X 处理器,提供 112 条 PCI Express 5.0 通道。每块 RTX Pro 6000 GPU 均使用一个 x16 PCIe Gen5 插槽,SSD 则使用 U.2 x4 接口。该服务器的配置属于基础配置,预留了充足的扩展空间,例如可添加额外的 aiDAPTIVCache SSD 和 GPU 以提升性能。.
在 SC25 大会上,aiDAPTIVCache SSD 使用的是 8TB U.2 型号,这是处理 4050 亿参数模型训练所需的容量。LLM 模型的微调训练所需的内存容量约为参数数量的 20 倍。在这种情况下,4050 亿参数相当于大约 8TB 的内存。这些内存通常是显存(VRAM),在某些情况下也可能是系统内存(RAM),但如此大容量的显存和系统内存都非常昂贵。aiDAPTIV+ 通过 8TB 的 NAND 闪存来扩展可用内存。.
如果采用传统的将所有数据保存在显存(VRAM)中的方法,而不是使用 aiDAPTIV+,训练一个 405 亿字节的模型大约需要 26 个最新的 NVIDIA B300 Ultra 加速器,这意味着需要四台服务器,每台服务器配备八个 GPU——而每个 GPU 的成本就相当于整个 aiDAPTIV+ 服务器。另一种方案是使用大约 40 个 NVIDIA B200 GPU(分布在五台服务器上)、53 个 H200 GPU(运行在七台服务器上)或 93 个 H100 加速器(安装在十二台 HGX H100 服务器中)。此外,还需要所有网络和互连硬件,总功耗在 40 kW 到 80 kW 之间。而 aiDAPTIV+ 服务器仅消耗约 1 kW 的功率,且无需任何额外的基础设施。.
aiDAPTIV+ 训练结果和表现
Phison 使用 Hugging Face 网站上的 Dolly 创意写作基准测试数据集,对 Llama 3.1 405B LLM 模型进行了微调,以用于 SC25 演示。不同的数据集会影响训练所需的时间,但不同硬件解决方案的扩展性仍然相似。.
基础的 Llama-3.1-405B-Instruct 模型大小为 2 TB,采用 Safetensors 格式。训练过程的第一步是将 LLM 张量解包到内存中——在本例中是解包到 aiDAPTIVCache SSD 中。这会产生超过 5 TB 的数据,生成时间约为 30 分钟,训练过程中内存使用峰值超过 7 TB。.
Dolly 数据集包含 77.1 万个字符和 672 个问答对,aiDAPTIV+ 服务器以每轮 25 小时 50 分钟的速度完成了微调训练。整个过程耗时两天四小时,训练周期为两轮。.
在 aiDAPTIV+ 服务器以 SC25 频率运行的四天里,aiDAPTIV+ 向 aiDAPTIVCache SSD 写入了数百 TB 的数据。对于额定写入量为 1 DWPD 的典型企业级 SSD 而言,这种写入量会在几周内耗尽闪存——容量较小的硬盘损耗速度会更快。Pascari aiDAPTIVCache SSD 的耐久性评级高达 100 DWPD,专为应对此类工作负载而设计,可 24/7/365 全天候运行长达五年。.

Pascari AI200E 8TB U.2 SSD 用于 Llama 405B 的微调训练。.
使用 aiDAPTIV+ 开始做更多事情
aiDAPTIV+ 为扩展用于微调训练的可用内存提供了一条重要途径。鉴于全球 DRAM 短缺导致内存价格飙升,aiDAPTIV+ 的成本仅为传统 DRAM 的一小部分。它为企业在各个层面利用人工智能开辟了新的途径,用户可以使用本地硬件,无需巨额资金投入、数据中心或大量电力。aiDAPTIV+ 也适用于科研和教育机构,使用户能够在无需支付昂贵的云服务费用或担心数据主权问题的情况下,对更大规模的模型进行实验。.
Phison 在 SC25 大会上的演示证明,无需庞大的数据中心和昂贵的基础设施即可运行最大型的 AI 模型。aiDAPTIV+ 将专用的 aiDAPTIVCache SSD 与智能内存编排相结合,为以往只有超大规模数据中心才能实现的模型微调提供了一条切实可行且经济实惠的途径。对于希望解锁更大型模型并真正实现本地 AI 独立性的企业而言,aiDAPTIV+ 代表着 AI 领域的一次重大变革。.
访问群汇 探索 aiDAPTIV+ 如何改变您的 AI 工作流程,并了解该技术的实际应用。.






