
Die Bedingungen Künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden in der Computerbranche immer häufiger eingesetzt, aber selbst erfahrene IT-Praktiker sind sich möglicherweise nicht vollständig der Computer- und Speicherinfrastruktur bewusst, die zur Unterstützung der beiden Technologien erforderlich ist. Dieser Artikel untersucht das Problem und bietet Einblicke in die Art und Weise, wie Solid-State-Laufwerke (SSDs) die besten KI- und ML-Ergebnisse ermöglichen.

Was sind KI und ML?
Der erste Schritt zum Verständnis der wahren Natur von KI und ML besteht darin, zu begreifen, dass sie nicht dasselbe sind. Bei KI geht es darum, Software zu entwickeln, die wie ein Mensch denken kann. Bei ML geht es darum, Software dazu zu bringen, neue Konzepte zu erlernen und diese Konzepte dann immer besser zu beherrschen. Es handelt sich um unterschiedliche, aber verwandte und sich überschneidende Technologien.
Auch KI und ML sind keine neuen Ideen. Der Computervisionär Alan Turing postulierte bereits 1950, dass Maschinen dazu gebracht werden könnten, wie Menschen zu denken. 1959 führte der KI-Pionier Marvin Minsky die Analysis-Prüfung für Erstsemester am MIT für ein sehr frühes KI-Programm durch. Es ist vergangen. Filme haben uns den mörderisch intelligenten HAL 9000 beschert 2001: Odyssee im Weltraum und das ebenso tödliche Skynet in Der Terminator. Diese Beispiele sind erwähnenswert, da die Fiktion unsere Denkweise über KI und ML geprägt hat, dabei aber auch für einige Verwirrung gesorgt hat.
Glücklicherweise haben wir das Zeitalter von Skynet noch nicht erreicht, aber unsere Welt ist voller beeindruckender Beispiele für die Arbeit von KI und ML. Die meisten davon sind weder groß noch auffällig, haben aber nicht weniger Auswirkungen auf das Geschäft und unser tägliches Leben. Ein „Robotic Process Automation“ (RPA) „Bot“ kann beispielsweise mithilfe von KI Aufgaben wie das Lesen von E-Mail-Nachrichten und das Ausfüllen von Formularen ausführen. ML treibt Prozesse wie die Gesichtserkennung bei der Strafverfolgung oder die Krebsdiagnose im medizinischen Bereich voran.
Wie funktionieren KI und ML?
Obwohl es viele Varianten der KI- und ML-Programmierung gibt, basieren beide Technologien im Kern auf der Mustererkennung. Im Beispiel des RPA-E-Mail-Lesens wird der Bot darauf trainiert, Phrasen in einer E-Mail-Nachricht zu erkennen, die beschreiben, worum es geht. Eine Nachricht mit den Worten „Zahlung“ oder „überfällig“ ist für die Buchhaltung bestimmt.
Der Bot kann auch die E-Mail-Signatur analysieren und mithilfe der Mustererkennung feststellen, ob die Nachricht von einem Lieferanten (Kreditorenbuchhaltung) oder einem Kunden (Debitorenbuchhaltung) stammt. Diese Art von Fähigkeit ist auch im Bereich der Cybersicherheit nützlich, wo KI-Software Millionen von Datenpunkten aus Sicherheitsprotokollen untersuchen und anomales Verhalten erkennen kann, das darauf hindeutet, dass ein Angriff im Gange ist.
ML nutzt in ähnlicher Weise die Mustererkennung, um ein bestimmtes Wissensgebiet besser zu verstehen. ML-Systeme können etwas über Daten lernen und kontinuierlich „intelligenter“ werden, ohne programmierten Code oder bestimmte Regeln befolgen zu müssen. Beispielsweise kann ein ML-Algorithmus eine Million Bilder von Bäumen und Pflanzen „betrachten“. Irgendwann wird sich der Algorithmus selbst den Unterschied zwischen einem Baum und einer Pflanze beibringen. Der wesentliche Unterschied zwischen KI und ML besteht daher darin, dass der KI beigebracht wurde, Muster zu erkennen, während ML noch lernt und besser darin wird, Muster zu erkennen.
All dies erfordert den Umgang mit enormen Datenmengen. In gewisser Weise sind KI und ML lediglich Erweiterungen des Big-Data-Paradigmas. Big Data und Datenanalysen ermöglichen es, große, vielfältige Datensätze zu interpretieren, visuelle Trends zu entdecken und neue Erkenntnisse zu gewinnen. KI und ML gehen noch einen Schritt weiter. Sie nutzen bestehende Big-Data-Analyse- und Data-Science-Prozesse wie Data Mining, statistische Analysen und prädiktive Modellierung, um Schlussfolgerungen, Entscheidungsfindung und Handlungsschritte auf der Grundlage von Big Data zu ermöglichen.

In der Praxis umfassen KI und ML vier separate Prozesse, die jeweils ein Datenmanagement beinhalten:
- Datenaufnahme – Überführung von Daten aus mehreren Quellen in Big-Data-Plattformen wie Spark-, Hadoop- und NoSQL-Datenbanken, die Grundlage für KI- und ML-Workloads
- Vorbereitung – Vorbereitung der Daten für die Verwendung im KI- und ML-Training
- Training – Ausführen der Trainingsalgorithmen von KI- und ML-Softwareprogrammen
- Inferenz – KI- und ML-Software dazu bringen, ihre Inferenz-Workflows auszuführen

Warum NAND-Flash-Speicher für KI und ML unerlässlich ist
Die zentrale Rolle von Big Data in KI und ML macht Speicher zu einem entscheidenden Erfolgsfaktor für diese Workloads. Ohne effektiven, flexiblen und leistungsstarken Speicher wird KI- und ML-Software keine gute Leistung erbringen. Zumindest werden die Arbeitslasten die Rechen- und Speicherinfrastruktur nur unzureichend nutzen.
Aus diesen Gründen ist NAND-Flash-Speicher das ideale Medium für Speicher, der KI und ML unterstützt. Um zu verstehen, warum, betrachten Sie die Speicheranforderungen in jeder der vier Phasen von KI und ML.
Bei der Datenaufnahme erfasst die KI große, sehr unterschiedliche Datensätze, darunter strukturierte und unstrukturierte Datenformate. Daten können aus einer potenziell breiten Palette von Quellen stammen. Für eine erfolgreiche Aufnahme ist ein hohes Speichervolumen erforderlich, gemessen vielleicht in Petabytes oder sogar Exabytes, aber auch mit einer schnellen Ebene für Echtzeitanalysen. Zuverlässigkeit ist hier, wie auch bei den anderen drei Stufen, von entscheidender Bedeutung. NAND-Flash bietet die beste Mischung aus Zuverlässigkeit und Verarbeitungsgeschwindigkeit.
Die Datenvorbereitungsphase von KI und ML bedeutet, die aufgenommenen Rohdaten zu transformieren und für die Verwendung durch die neuronalen Netze der KI- und ML-Software in der Trainings- und Inferenzphase zu formatieren. Die Geschwindigkeit der Dateieingabe/-ausgabe (E/A) ist in der Datenvorbereitungsphase wichtig. NAND-Flash bietet in diesem Anwendungsfall eine gute Leistung.
Die Trainings- und Inferenzphasen von KI und ML sind in der Regel rechenintensiv. Sie erfordern ein Hochgeschwindigkeits-Streaming von Daten in Trainingsmodelle in der Software. Es handelt sich um einen iterativen Prozess mit vielen Stopps und Starts, die allesamt die Speicherressourcen belasten können, wenn sie nicht für die Aufgabe geeignet sind.
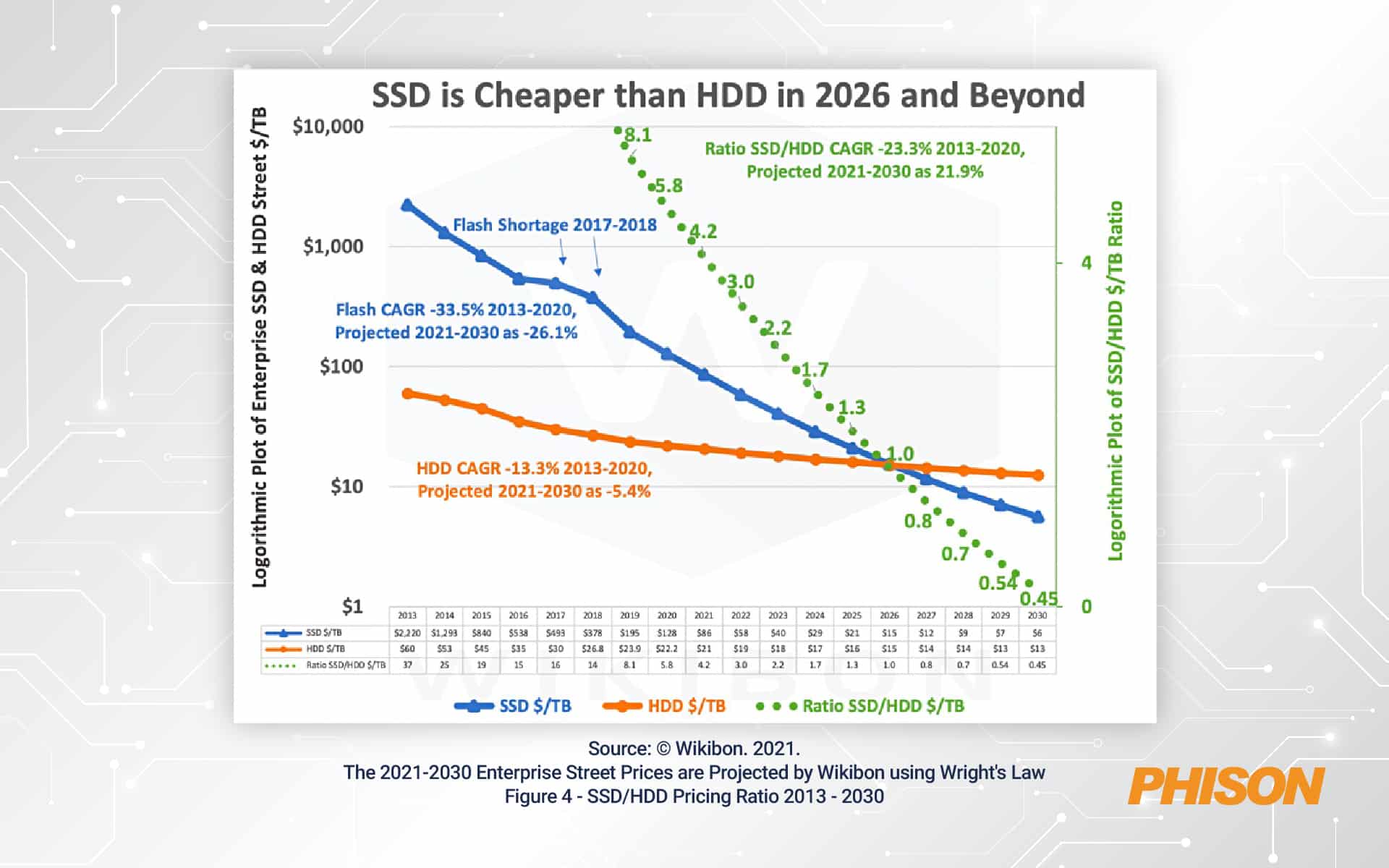
Wie SSDs den Erfolg von KI und ML ermöglichen
Das Ausmaß von Datenspeicher Der für KI- und ML-Projekte erforderliche Bedarf spricht im Allgemeinen für einen Mix aus Speicherlösungen. Ein mehrstufiger Ansatz ist oft am besten, wobei einige leistungsschwächere und kostengünstigere Speicher weniger relevante Daten speichern. Es muss jedoch auch eine Hochleistungsschicht vorhanden sein, die im Verhältnis wahrscheinlich größer ist, als sie normalerweise in einem Big-Data-Ökosystem zu finden ist.
Dies bedeutet den Einsatz von SSDs auf einer bedeutenden Ebene der KI/ML-Speicherumgebung. Nur eine SSD kann die erforderliche Leistung und Latenz liefern, um die schnelle Übertragung riesiger Datenmengen zu unterstützen, die in der Trainingsphase in KI- und ML-Software eingespeist werden. Wenn der Prozess zur Inferenzierung übergeht, werden Leistung und Latenz noch wichtiger – insbesondere, wenn die Reaktionszeit des KI-/ML-Systems in einem anderen Workflow eine kritische Rolle spielt. Wenn Menschen und andere Systeme darauf warten, dass ein träges KI- oder ML-System seine Arbeit erledigt, leiden alle darunter.

Wie Phison helfen kann
Die anpassbaren SSD-Lösungen von Phison Bieten Sie die Art von überlegener Leistung und Flexibilität, die für den Erfolg bei KI- und ML-Workloads erforderlich ist. Angesichts der Tatsache, dass KI/ML-Speicher tendenziell eher lese- als schreibintensiv sind, sticht Phison als einziger Anbieter eines 2,5-Zoll-SATA-SSD-Laufwerks mit 15,36 TB und 7 mm hervor, das für leseintensive Anwendungen zu einem guten Preis-Leistungs-Verhältnis optimiert ist.
Wie in der realisiert Phison ESR1710-SerieEs bietet die höchste Rack-Speicherdichte und einen geringen Stromverbrauch – beides wesentliche Bestandteile einer wirtschaftlichen, aber leistungsstarken Speicherung, die von KI und ML benötigt wird. Die einzigartigen Abmessungen der 2,5-Zoll-SATA-SSD von Phison, die über die weltweit höchste Kapazität für eine SSD dieser Größe verfügt, ermöglichen die Speicherung von bis zu 13 PB Daten für KI- und ML-Anwendungen in einem einzigen 48U-Rack. Diese Art der Dichte führt zu einer günstigen Speicherökonomie für KI und ML.
Für KI/ML-Anwendungen, die das Absolute erfordern schnellstes PCIe Gen4x4 Lese- und Schreibgeschwindigkeiten und mit dem branchenweit niedrigsten Stromverbrauch liefert Phison jetzt das aus X1-SSD Serie im U.3-Formfaktor, der abwärtskompatibel mit U.2-Steckplätzen ist und über Kapazitäten von bis zu 15,36 TB verfügt.
Häufig gestellte Fragen (FAQ):
Wie verbessert NAND-Flash die Phasen der Datenaufnahme und -vorbereitung?
NAND-Flash ermöglicht Hochgeschwindigkeits-Ein-/Ausgabevorgänge und gewährleistet Zuverlässigkeit bei der Verarbeitung strukturierter und unstrukturierter Daten im Petabyte-Bereich. Es unterstützt die Transformation von Rohdaten in Formate, die von neuronalen Netzwerke effizient.
Warum sind SSDs beim Training von KI-Modellen effektiver als HDDs?
SSDs verarbeiten zufällige und sequentielle Datenzugriffe schneller, eine Notwendigkeit für iterative Trainingsschleifen, die im ML üblich sind. Ihre Fähigkeit, pflegen Die Leistung während E/A-intensiver Prozesse reduziert die Trainingszeit erheblich.
Wie unterscheidet sich Phisons aiDAPTIV+ von Cloud-basierten KI-Plattformen?
aiDAPTIV+ unterstützt lokalisiertes KI-Modelltraining vor Ort und bietet mehr Kontrolle, Datenschutz und niedrigere Gesamtbetriebskosten im Vergleich zu öffentlichen Cloud-Plattformen, bei denen Gebühren für die Rechen- und Speichernutzung anfallen.
Ist ein mehrstufiges Speichermodell für alle KI/ML-Systeme erforderlich?
Ja, ein Hybridmodell sorgt für Kosteneffizienz, indem weniger kritische Daten auf kostengünstigere Speichermedien ausgelagert werden, während SSDs für Echtzeit- oder hochprioritäre KI-Operationen reserviert werden. Es gleicht Leistung mit Budget.
Wie unterstützt Phison das LLM-Training (Large Language Model)?
Phisons Pascari AI SSDs sind speziell optimiert für die hoher Durchsatz Anforderungen der LLM-Ausbildung und gewährleistet eine gleichbleibende Leistung und beschleunigte Datenverarbeitung während iterativer Lernzyklen.






