
SC25において、Phison社は、2基のGPUと192GBのVRAMを搭載した単一サーバー上で、Llama 3.1の4050億パラメータモデルを微調整学習することで、同社のaiDAPTIV+ハードウェアおよびソフトウェアソリューションのポテンシャルを披露しました。このタスクには通常、合計7TBを超えるVRAMプールと複数のNVIDIAサーバーが必要となり、大規模でコストのかかるセットアップとなります。しかし、aiDAPTIV+のパワーにより、$50,000ドル程度の単一システムで全て実行できました。.
この成功の秘訣は、LLMの計算された重みと値を保存するために使用された8TBのaiDAPTIVCache SSDでした。aiDAPTIV+は、すべてをVRAMに収めようとするのではなく、複雑な微調整タスクをより小さく、より管理しやすいチャンクに分割します。その結果、幅広い組織がより強力なAIモデルにアクセスできるようになります。.
aiDAPTIV+がLLMファインチューン学習にもたらす汎用性の一例として、このシステムは、通常であれば8基のH100 GPUを搭載したNVIDIA HGX H100サーバー12台が必要となるタスクを完了しました。これらのサーバーは、Phisonブース内で同じタスクを実行したaiDAPTIV+サーバーよりもはるかに多くのスペースと電力を必要とし、コストも大幅に高くなります。.

aiDAPTIV+とは何ですか?
aiDAPTIV+は、AIモデルの微調整学習のためのメモリ空間を拡張し、推論ワークロードのTTFT(Time to First Token)を高速化するように設計されたハードウェアおよびソフトウェアソリューションです。専用のaiDAPTIVCache SSDは、学習用のLLMのテンソル重みとベクトルをアンパックするためのステージング領域として機能します。aiDAPTIVLinkミドルウェアはメモリ割り当てを管理し、利用可能なリソースを最大限に活用する方法を決定し、必要に応じてaiDAPTIVCache SSDとの間でデータをVRAMまたはDRAMに転送します。.
aiDAPTIVCache SSDは、このタスク専用に設計されており、100 DWPD(ドライブ書き込み/日)という極めて高い耐久性を備えています。このレベルの耐久性と、安定した高速スループットの可用性は、SLC NANDを採用することで実現しています。高負荷使用時には、aiDAPTIVCache SSDに1日あたり300TB以上の書き込みが可能です。これは、一般的なSSDであれば2ヶ月足らずで焼き切れてしまう量です。aiDAPTIVCacheドライブは、この過酷なシナリオにおいて5年間の連続使用に耐えられるように設計されています。.
純粋なGPU VRAMを使用する場合と比較して、微調整トレーニングの完了時間は長くなりますが、パフォーマンス低下の大部分はGPU数と利用可能な計算量が少ないことに起因しています。aiDAPTIVCache SSDは深刻なボトルネックを引き起こさないほど高速であるため、同数のGPUを使用した純粋なGPUベースのトレーニングと比較して、トレーニング時間は約5%長くなります。ただし、aiDAPTIV+は、そうでなければデータセットの微調整が不可能なGPU上で、はるかに大規模なモデルを使用できるため、直接比較することは特に意味がありません。.

2 つの RTX 4000 Ada GPU で Pro Suite を実行している aiDAPTIV+ AITPC。.
Llama 3.1 405B aiDAPTIV+ サーバートレーニングの詳細
SC25 で Phison が使用したサーバーには、Llama 3.1 405B モデルのトレーニングを可能にする次のハードウェアが搭載されていました。.
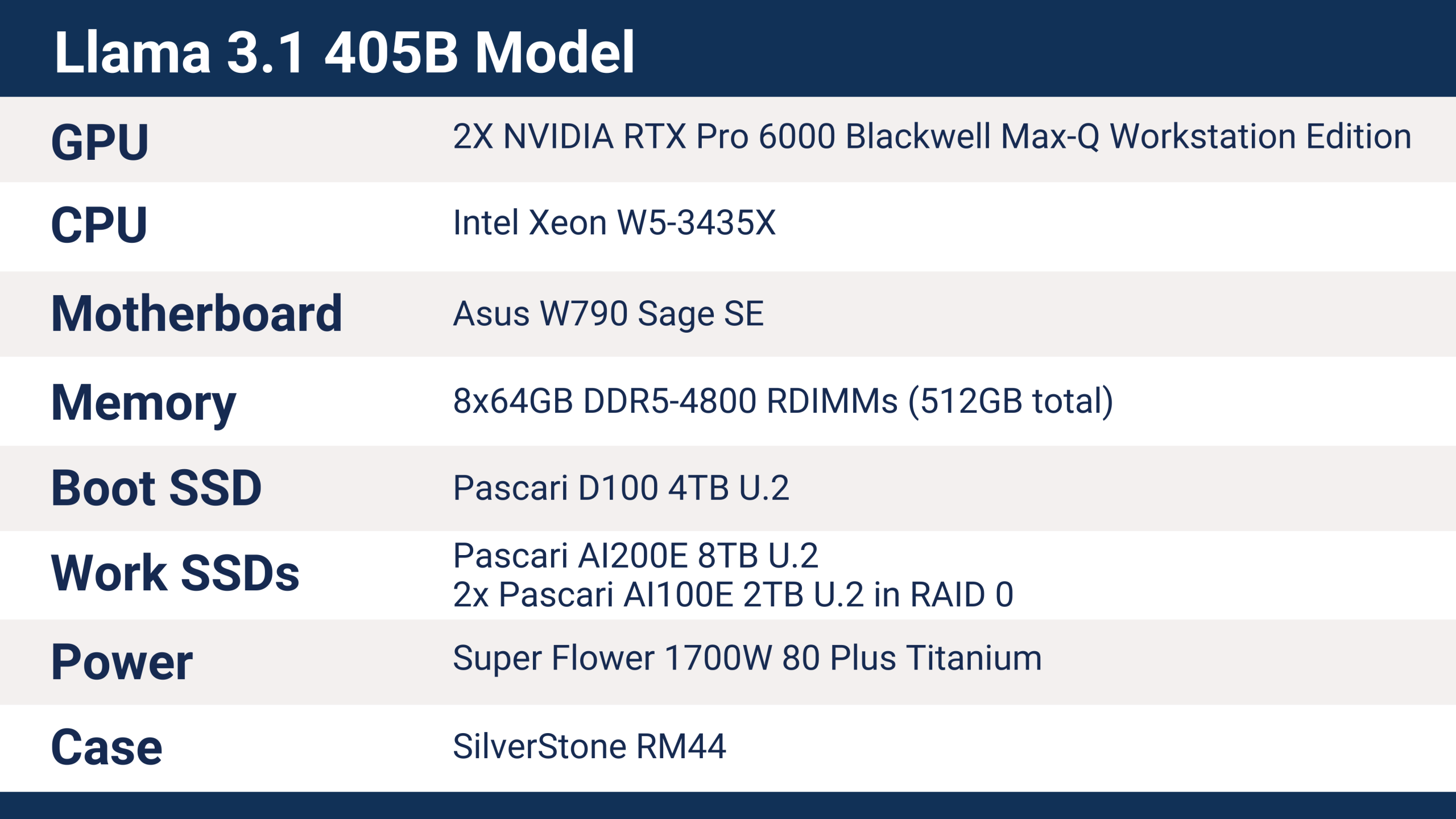
aiDAPTIV+は、IntelおよびAMDのCPU、ARMプロセッサ、様々なマザーボードとチップセット、そして幅広いメモリ容量など、様々な最新プラットフォームをサポートしています。CPUはaiDAPTIV+の実行において重要な要素ではありませんが、ワークステーションやサーバープラットフォームでは、より幅広い接続オプションが提供されます。クライアントソリューションは動作しますが、サポートするPCIeレーン数は限られており、特に複数のGPUと複数のSSDを使用する場合、ストレージデバイスとGPUのパフォーマンスに直接的な影響を与えます。.
Phison SC25サーバーは、Sapphire RapidsファミリーのIntel Xeon W5-3435Xプロセッサーを搭載し、合計112レーンのPCI Express 5.0接続を提供します。RTX Pro 6000 GPUはそれぞれx16 PCIe Gen5スロットを使用し、SSDはU.2 x4接続を使用しています。このサーバーはベースライン構成に近い構成で、追加のaiDAPTIVCache SSDやGPUによるパフォーマンス向上など、拡張オプションを十分に備えています。.
SC25で使用されたaiDAPTIVCache SSDは8TBのU.2モデルで、4050億パラメータのモデルのトレーニングを処理するのに必要な容量でした。LLMの微調整トレーニングには、パラメータ数の約20倍のメモリ容量が必要です。この場合、4050億パラメータは約8TBのメモリに相当します。このメモリは従来、VRAM、または場合によってはシステムRAMでしたが、どちらもそのような量になると非常に高価です。aiDAPTIV+は、利用可能なメモリを8TBのNANDフラッシュストレージで増強します。.
405Bモデルを学習させるには、最新のNVIDIA B300 Ultraアクセラレータを約26基必要とします。従来のアプローチでは、すべてのデータをVRAMに保持し、aiDAPTIV+は使用しません。つまり、8基のGPUを搭載したサーバーを4台使用することになります。そして、個々のGPUのコストはaiDAPTIV+サーバー全体と同額になります。あるいは、5台のサーバーに分散して約40基のNVIDIA B200 GPU、7台のサーバーで53基のH200 GPU、または12台のHGX H100サーバーに93基のH100アクセラレータが必要になります。また、ネットワークと相互接続のためのハードウェアもすべて必要となり、総消費電力は40kWから80kWの範囲になります。aiDAPTIV+サーバーの消費電力は約1kWで、追加のインフラストラクチャは必要ありません。.
aiDAPTIV+のトレーニング結果とパフォーマンス
Phisonは、Hugging Faceで使用されているDollyクリエイティブライティングベンチマークを使用して、SC25デモ用にLlama 3.1 405B LLMを微調整しました。データセットによってトレーニングに必要な時間は異なりますが、ハードウェアソリューションが異なってもスケーリングはほぼ同等です。.
ベースとなるLlama-3.1-405B-Instructモデルは、Safetensors形式を使用して2TBのサイズです。学習プロセスの最初のステップは、LLMテンソルをメモリ(この場合はaiDAPTIVCache SSD)に展開することです。これにより5TBを超えるデータが生成され、生成には約30分かかります。学習プロセス中のピーク時には、7TBを超えるメモリ使用量が発生します。.
Dollyデータセットは77万1千文字と672のQ/Aペアで構成されており、aiDAPTIV+サーバーは1エポックあたり25時間50分の速度で微調整トレーニングを完了しました。全体のプロセスは2エポックのトレーニング実行で2日4時間で完了しました。.
SC25でaiDAPTIV+サーバーが稼働した4日間で、aiDAPTIV+はaiDAPTIVCache SSDに数百テラバイトのデータを書き込みました。1DWPD(1DWPD)の一般的なエンタープライズSSDの場合、このレベルの書き込みでは数週間でフラッシュメモリが消耗してしまいますが、低容量ドライブであればそれよりも短い期間で消耗します。100DWPDの耐久性を誇るPascari aiDAPTIVCache SSDは、この種のワークロードに対応するように設計されており、5年間、24時間365日稼働可能です。.

Llama 405B の微調整トレーニングに使用される Pascari AI200E 8TB U.2 SSD。.
aiDAPTIV+でもっと多くのことを始めましょう
aiDAPTIV+は、微調整学習のためのメモリ拡張に重要な手段を提供します。世界的なDRAM不足によりメモリ価格が高騰している中、aiDAPTIV+はそれをわずかなコストで実現します。莫大な資金、データセンター、大量の電力を必要としないオンプレミスのハードウェアを使用することで、ビジネスのあらゆるレベルでAIを活用する可能性を広げます。aiDAPTIV+は研究・教育機関にも適しており、高額なクラウド契約やデータ主権の懸念なしに、より大規模なモデルを用いた実験を可能にします。.
Phison社のSC25デモンストレーションは、最大規模のAIモデルを扱うために大規模なデータセンターや高額なインフラは必要ないことを証明しています。aiDAPTIV+は、専用に設計されたaiDAPTIVCache SSDとインテリジェントなメモリオーケストレーションを組み合わせることで、かつてはハイパースケーラーのみが実行可能とされていたモデルの微調整を、実用的かつ低コストで実現します。より大規模なモデルと真のオンプレミスAI独立性を実現したい組織にとって、aiDAPTIV+は可能性を大きく変える力となります。.
フィソンを訪問 aiDAPTIV+ が AI ワークフローをどのように変革できるかを探り、テクノロジーの実際の動作を確認してください。.






