
Heutzutage verlassen sich die Menschen auf Big-Data-Anwendungen, um verschiedene Arten von Diensten zu nutzen. Nehmen Sie zum Beispiel den berühmten Lieferroboter Amazon Scout. Wir können jetzt Pakete ohne menschliches Zutun empfangen.
Es ist nicht schwer vorstellbar, dass durch die steigende Nachfrage nach verschiedenen Dienstleistungen in unserem täglichen Leben mehr unverarbeitete Daten erzeugt werden. Die International Data Corporation (IDC) prognostiziert, dass die weltweiten Daten bis 2025 enorm auf 175 ZB ansteigen werden. Die ständig wachsenden Datenmengen werden so zu einem Faktor, der die Entwicklung von Computational Storage vorantreibt. Hierbei handelt es sich um ein hochmodernes Speichersystem, das die Datenverarbeitung beschleunigen, Echtzeitanalysen effizienter machen und die Zeit verkürzen kann, die wir auf unser Paket und unsere Daten warten.
Die Unterscheidung zwischen konventionellen und Computational Storage-Modellen
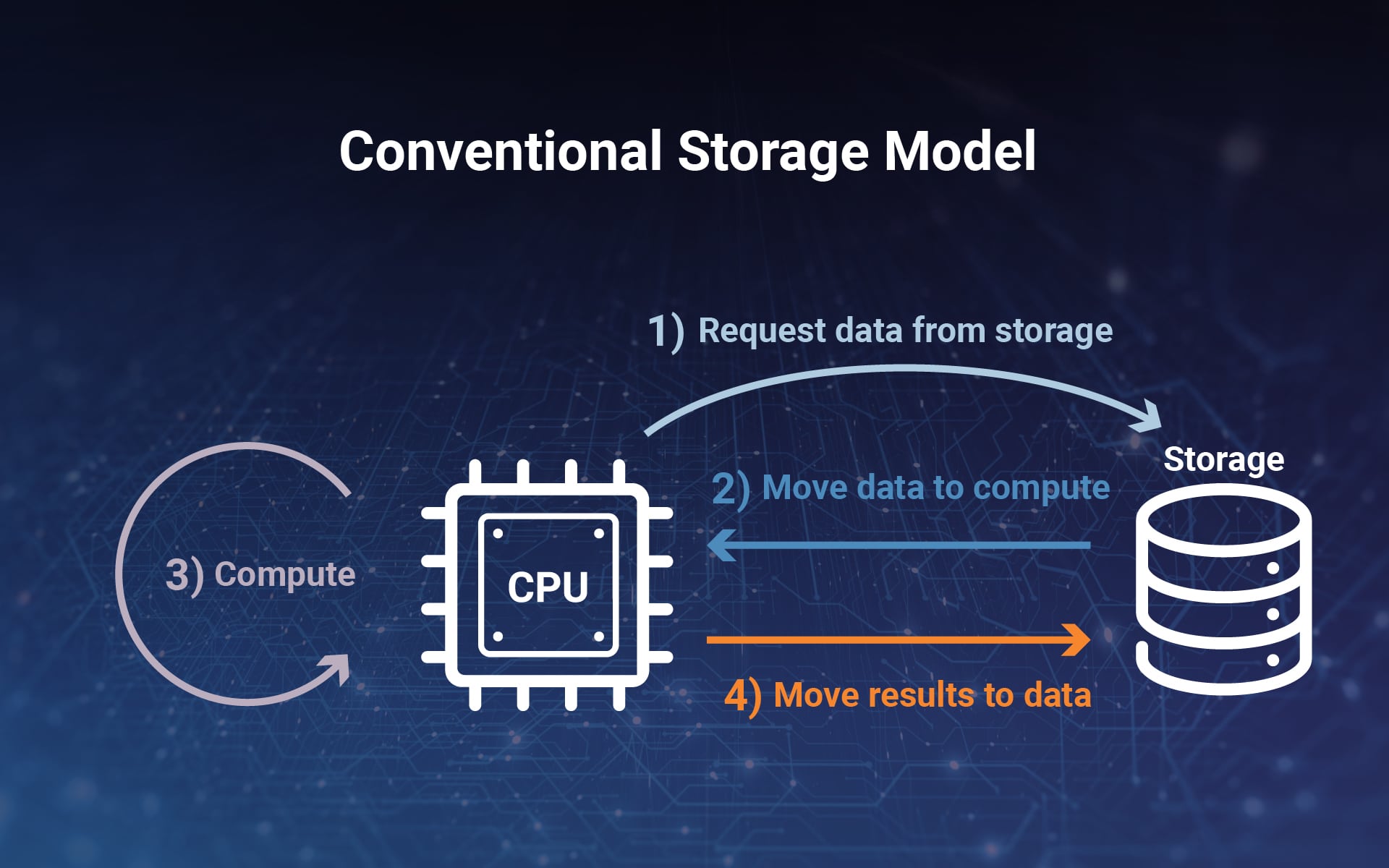
In der herkömmlichen Computerarchitektur werden Daten häufig zwischen Speichersystemen und Speichereinheiten der Anwendungsserver verschoben. Die CPU fordert die Daten zunächst vom Speichersystem an, bevor sie zur Berechnung an die CPU übertragen werden. Nachdem die CPU die Verarbeitung abgeschlossen hat, werden die Ergebnisse zur Speicherung an das Speichersystem zurückgesendet. Dieser Vorgang kann tausende Male wiederholt werden. Die hohen Kosten für das Verschieben von Daten während dieser sich wiederholenden Schritte können zu einem zusätzlichen Energieverbrauch führen und die Leistung von Big-Data-Anwendungen beeinträchtigen.
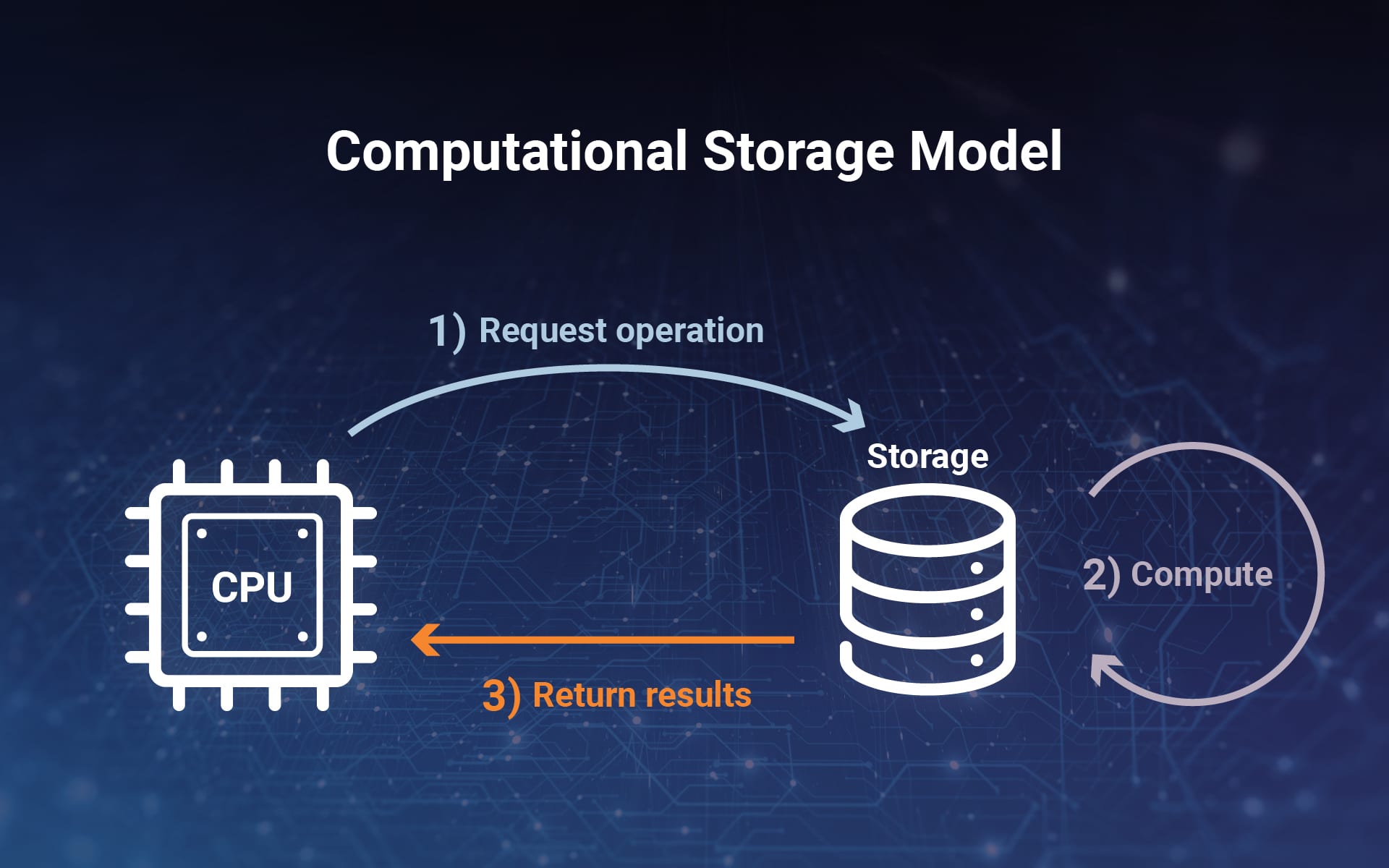
Im Gegensatz zum herkömmlichen Speichermodell verlagert das Computational Storage-Modell die Verarbeitung in das Datensystem und es werden keine Daten an die CPU gesendet. Dies bedeutet, dass Daten-Workloads direkt auf dem Speichercontroller verarbeitet werden. Ziel ist es, die Daten dort zu analysieren und zu verarbeiten, wo sie sich befinden.
So funktioniert es. Die CPU sendet eine Anfrage an das Speichersubsystem, die Daten müssen das Speichersystem jedoch nicht verlassen. Stattdessen wird der Vorgang vom Antrieb selbst ausgeführt. Computational Storage spart erheblich Zeit und Energie, indem es die komplexen und sich wiederholenden Schritte eliminiert, die das Hin- und Herschicken großer Datenmengen über ein Netzwerk erfordern.
Die Komponenten von Computational Storage
-
-
- Computational Storage Drives (CSD): Ein CSD ist ein Computational Storage-Gerät, das entweder einen ASIC oder einen in ein Speichergerät eingebetteten Mikroprozessor darstellt. Es kann Berechnungen im Speichersystem durchführen und unterstützt die dauerhafte Datenspeicherung.
-
-
-
- Computational Storage Processors (CSP): Ein CSP ist ein Prozessor, der als Controller einer Reihe von SSDs fungiert. Dabei handelt es sich um eine Komponente, die Rechendienste und Funktionen für ein zugehöriges Speichersystem bereitstellt, aber keine dauerhafte Datenspeicherung bietet
-
-
-
- Computational Storage Arrays (CSA): Ein CSA ist eine Sammlung von CSD und CSP, die sowohl Rechenleistung als auch Speicher mit optionalen Speichergeräten und der Steuerungssoftware enthält.
-
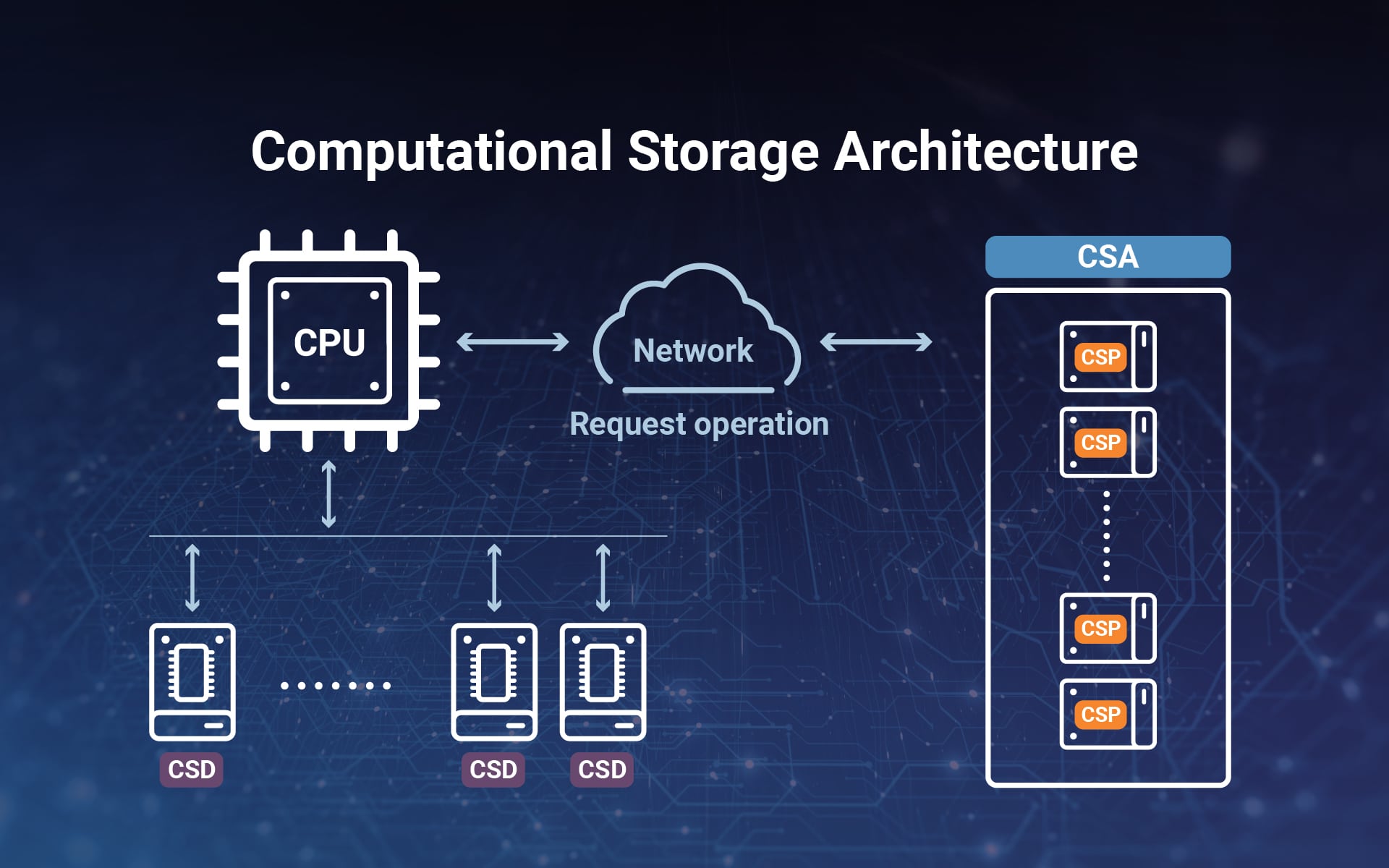
Kurz gesagt handelt es sich bei Computational Storage um ein Speichersubsystem, das mehrere auf den Speichermedien befindliche CPUs, Computational Storage-Arrays oder deren Controller vereint.
Drei Hauptvorteile von Computational Storage
1. Mindestbandbreite und Leistung: Durch die Verwendung von Computational Storage werden Daten nicht so häufig über die Schnittstelle verschoben, sodass der Benutzer mehr Daten auf dem Laufwerk zuweisen kann. Durch die Reduzierung der Datenbewegung zwischen Speicher und Haupt-CPU muss nur das Endergebnis an den Host übermittelt werden. Computerspeicher bietet erhebliche Energieeinsparungen und zusätzliche I/O-Bandbreite.
2. Latenz beseitigen: Da die Speichergröße in der Regel den Speicher um ein Vielfaches übersteigt, müssen die Daten in Blöcken gelesen werden. Dies verlangsamt die Echtzeit-Datenanalyse und beeinträchtigt die Effizienz des Hochleistungsrechnens. Computational Storage kann diese Engpässe jedoch beseitigen. Indem die Verarbeitung auf das Speichersubsystem selbst verlagert wird, können riesige Datenmengen dort verarbeitet werden, wo die Daten ihren Ursprung haben. Es verkürzt die Zeit, die zum Verschieben, Analysieren und Verarbeiten der Daten benötigt wird, was die Latenz und die Auslastung der Netzwerkbandbreite erheblich verbessert.
3. Datenzentriertes Computing: Im Gegensatz zur computerzentrierten Architektur sind datenzentrierte Architekturen darauf ausgelegt, riesige Datenmengen zu analysieren, wobei der Schwerpunkt auf dem ersten Datenkonzept liegt. Durch die Installation von Verarbeitungsfunktionen direkt in der Speicheranwendung kann Computational Storage CPU-Zyklen für die übergeordneten Funktionen und Aufgaben freigeben und Parallelität für bestimmte Arbeitslasten ermöglichen, die Durchsatz und Leistung verbessern.

Der Phison-Ansatz
Apropos all diese oben genannten Vorteile: Phison, als eines der führenden Unternehmen der Computerbranche, wird in Kürze eine Komplettlösung für Computational Storage auf den Markt bringen. Phison hat dies erreicht, um einen breiten und sofortigen Einsatz dieser neuen und innovativen Technologie zu ermöglichen. Wir arbeiten mit vielen aktuellen Serverherstellern zusammen, um Kunden schlüsselfertige Lösungen anzubieten. Die neue Technologie kann nicht nur den Netzwerkverkehr und die parallele Datenverarbeitung reduzieren, sondern auch andere Einschränkungen bei Datenverarbeitung, E/A, Arbeitsspeicher und Datenspeicherung verringern. Phison wird die beste Plattform und das breiteste Lösungsspektrum für alle Rechenzentren und Cloud-Dienstanbieter bieten, um umfangreichere Datenanwendungen optimal zu nutzen.






