
Auf der SC25 demonstrierte Phison das Potenzial seiner Hardware- und Softwarelösung aiDAPTIV+ durch das Feinabstimmen des Trainings des 405 Milliarden Parameter umfassenden Llama 3.1-Modells auf einem einzigen Server mit zwei GPUs und 192 GB VRAM. Normalerweise benötigt man für diese Aufgabe einen kombinierten VRAM-Pool von über 7 TB und mehrere NVIDIA-Server – eine aufwendige und kostspielige Konfiguration. Dank der Leistungsfähigkeit von aiDAPTIV+ konnte dies alles auf einem einzigen System realisiert werden, dessen Kosten sich auf rund 14.500.000 TP$ belaufen würden.
Der entscheidende Faktor für den Erfolg dieses Projekts war eine 8 TB große aiDAPTIVCache-SSD, die zur Speicherung der berechneten Gewichte und Werte für das LLM diente. aiDAPTIV+ zerlegt die komplexe Aufgabe des Feintunings in kleinere, besser handhabbare Abschnitte, anstatt alles im VRAM unterzubringen. Das Ergebnis ist ein demokratisierter Zugang zu leistungsfähigeren KI-Modellen für eine Vielzahl von Organisationen.
Um die Vielseitigkeit von aiDAPTIV+ für das LLM-Feinabstimmungstraining zu verdeutlichen: Dieses System bewältigte eine Aufgabe, für die normalerweise ein Dutzend NVIDIA HGX H100-Server mit jeweils acht H100-GPUs erforderlich wären. Diese Server benötigen deutlich mehr Platz und Strom und sind wesentlich teurer als der aiDAPTIV+-Server, der dieselbe Aufgabe am Phison-Stand erledigte.

Was ist aiDAPTIV+?
aiDAPTIV+ ist eine Hardware- und Softwarelösung zur Erweiterung des Speichers für das Feinabstimmen des Trainings von KI-Modellen und zur Beschleunigung der Time-to-First-Token (TTFT) bei Inferenz-Workloads. Ein spezieller aiDAPTIVCache-SSD dient als Zwischenspeicher für die entpackten Tensorgewichte und Vektoren des LLM für das Training. Die aiDAPTIVLink-Middleware verwaltet die Speicherzuweisung und optimiert die Nutzung der verfügbaren Ressourcen, indem sie Daten je nach Bedarf vom aiDAPTIVCache-SSD in den VRAM oder DRAM verschiebt.
aiDAPTIVCache SSDs sind speziell für diese Aufgabe entwickelt und zeichnen sich durch eine extrem hohe Lebensdauer von 100 Schreibvorgängen pro Tag (DWPD) aus. Diese hohe Lebensdauer und die konstant hohe Übertragungsgeschwindigkeit werden durch den Einsatz von SLC-NAND-Flashspeicher erreicht. Selbst bei intensiver Nutzung können über 300 TB pro Tag auf eine aiDAPTIVCache SSD geschrieben werden, was herkömmliche SSDs in weniger als zwei Monaten überlasten würde. aiDAPTIVCache-Laufwerke sind für einen fünfjährigen Dauerbetrieb unter diesen anspruchsvollen Bedingungen ausgelegt.
Die Dauer des Feinabstimmungstrainings ist zwar länger als bei der Nutzung von reinem GPU-VRAM, der größte Leistungsverlust resultiert jedoch aus der geringeren Anzahl an GPUs und der damit verbundenen geringeren Rechenleistung. Die SSDs des aiDAPTIVCache sind schnell genug, um keinen gravierenden Flaschenhals zu verursachen. Dadurch sind die Trainingszeiten etwa 51 TP3T länger als beim rein GPU-basierten Training mit einer ähnlichen Anzahl an GPUs. Direkte Vergleiche sind allerdings wenig aussagekräftig, da aiDAPTIV+ die Verwendung deutlich größerer Modelle auf GPUs ermöglicht, die den Datensatz sonst nicht feinabstimmen könnten.

aiDAPTIV+ AITPC mit Pro Suite auf zwei RTX 4000 Ada GPUs.
Llama 3.1 405B aiDAPTIV+ Server-Schulungsdetails
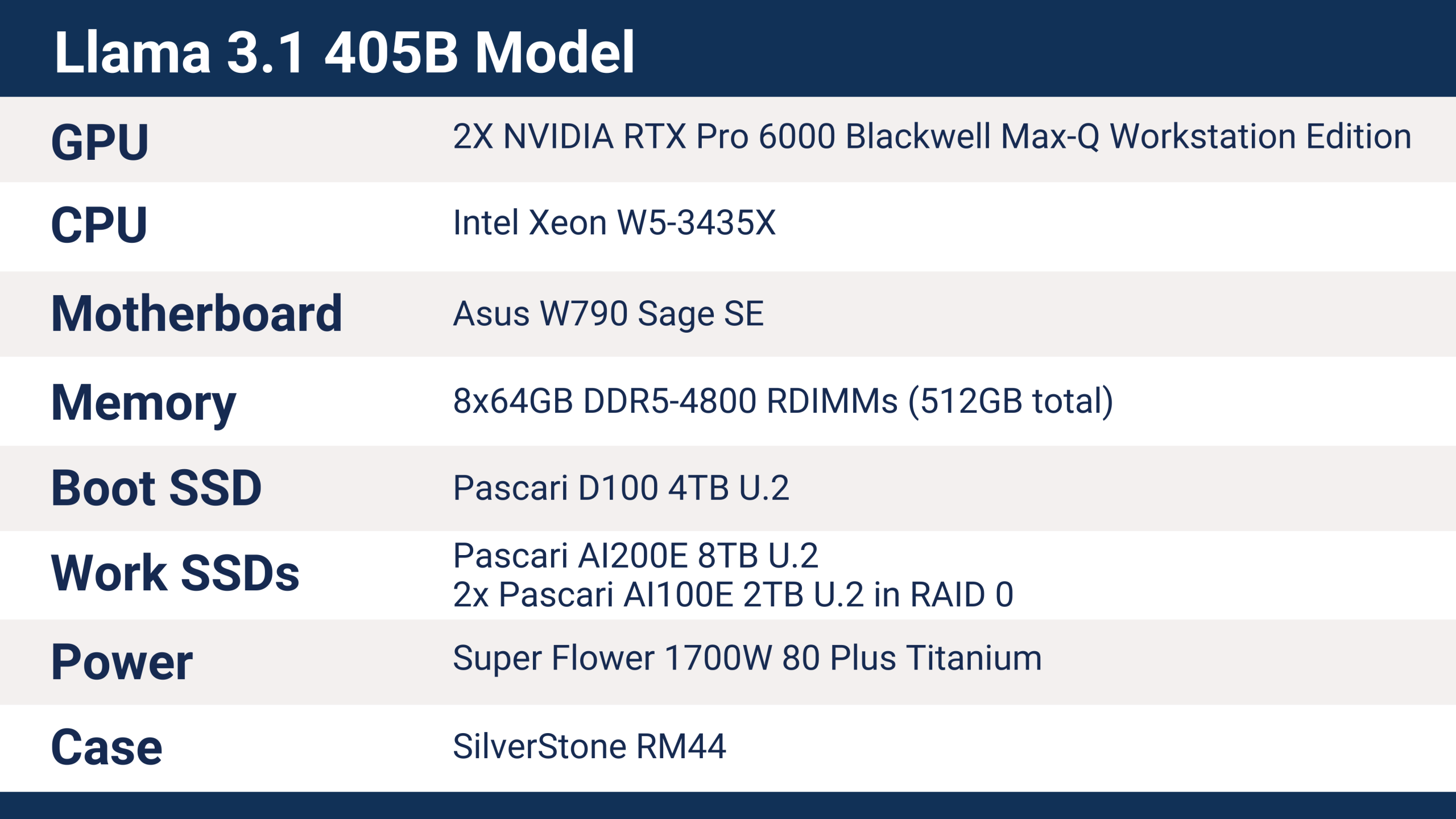
Der von Phison auf der SC25 eingesetzte Server verfügte über folgende Hardware, die das Training des Llama 3.1 405B-Modells ermöglichte.
aiDAPTIV+ unterstützt eine Vielzahl moderner Plattformen, darunter Intel- und AMD-CPUs, ARM-Prozessoren, verschiedene Mainboards und Chipsätze sowie Speicherkapazitäten unterschiedlicher Größe. Die CPU spielt für den Betrieb von aiDAPTIV+ keine entscheidende Rolle, Workstation- und Serverplattformen bieten jedoch deutlich mehr Anschlussmöglichkeiten. Client-Lösungen funktionieren zwar, unterstützen aber weniger PCIe-Lanes, was sich direkt auf die Leistung der Speichergeräte und GPUs auswirkt – insbesondere bei Verwendung mehrerer GPUs und SSDs.
Der Phison SC25 Server nutzt Intels Xeon W5-3435X Prozessor aus der Sapphire Rapids Familie, der 112 PCI-Express-5.0-Lanes bietet. Jede der RTX Pro 6000 GPUs belegt einen x16 PCIe-Gen5-Steckplatz, die SSDs sind über U.2 x4 angebunden. Die Serverkonfiguration stellt eher eine Basiskonfiguration dar und bietet viel Raum für Erweiterungsoptionen, darunter zusätzliche aiDAPTIVCache SSDs und GPUs zur Leistungssteigerung.
Die auf der SC25 verwendete aiDAPTIVCache SSD war ein 8-TB-U.2-Modell – die erforderliche Kapazität für das Training eines Modells mit 405 Milliarden Parametern. Das Feinabstimmen eines LLM erfordert etwa die 20-fache Speicherkapazität der Parameteranzahl. In diesem Fall entsprechen 405 Milliarden Parameter rund 8 TB Speicher. Üblicherweise handelt es sich dabei um VRAM oder in manchen Fällen um Arbeitsspeicher (RAM), die in solchen Mengen beide sehr teuer sind. aiDAPTIV+ erweitert den verfügbaren Speicher um 8 TB NAND-Flash-Speicher.
Für das Training eines 405-B-Modells mit einem herkömmlichen Ansatz, bei dem alle Daten im VRAM gespeichert werden, anstatt mit aiDAPTIV+, werden etwa 26 der neuesten NVIDIA B300 Ultra-Beschleuniger benötigt. Dies erfordert vier Server mit jeweils acht GPUs – wobei jede einzelne GPU so viel kosten würde wie der gesamte aiDAPTIV+-Server. Alternativ wären etwa 40 NVIDIA B200-GPUs auf fünf Servern, 53 H200-GPUs auf sieben Servern oder 93 H100-Beschleuniger auf zwölf HGX H100-Servern erforderlich. Hinzu kämen die gesamte Netzwerk- und Verbindungshardware mit einem Gesamtstromverbrauch zwischen 40 und 80 kW. Der aiDAPTIV+-Server hingegen verbrauchte nur etwa 1 kW und benötigte keine zusätzliche Infrastruktur.
Trainingsergebnisse und Leistung von aiDAPTIV+
Phison nutzte den Dolly Creative Writing Benchmark von Hugging Face, um das Llama 3.1 405B LLM für die SC25-Demonstration zu optimieren. Unterschiedliche Datensätze beeinflussen die Trainingszeit, die Skalierung wäre jedoch auf verschiedenen Hardwarelösungen ähnlich.
Das Basismodell Llama-3.1-405B-Instruct ist 2 TB groß und verwendet das Safetensors-Format. Der erste Schritt des Trainingsprozesses besteht darin, die LLM-Tensoren in den Arbeitsspeicher – in diesem Fall auf die aiDAPTIVCache-SSD – zu entpacken. Dies führt zu über 5 TB Daten und dauert etwa 30 Minuten. Der Speicherbedarf während des Trainingsprozesses kann in Spitzenzeiten über 7 TB betragen.
Der Dolly-Datensatz umfasst 771.000 Zeichen und 672 Frage-Antwort-Paare. Der aiDAPTIV+-Server führte das Feinabstimmungstraining mit einer Rate von 25 Stunden und 50 Minuten pro Epoche durch. Der gesamte Prozess war nach zwei Tagen und vier Stunden mit einem Trainingslauf von zwei Epochen abgeschlossen.
Während der vier Tage, in denen der aiDAPTIV+-Server mit SC25 lief, schrieb aiDAPTIV+ Hunderte von Terabytes an Daten auf die aiDAPTIVCache-SSD. Bei typischen Enterprise-SSDs mit einer Schreibgeschwindigkeit von 1 DWPD würde diese Schreibrate den Flash-Speicher innerhalb weniger Wochen verschleißen – bei Laufwerken mit geringerer Kapazität sogar noch schneller. Mit einer Lebensdauer von 100 DWPD sind die Pascari aiDAPTIVCache-SSDs optimal für diese Art von Arbeitslast ausgelegt und laufen fünf Jahre lang rund um die Uhr.

Pascari AI200E 8TB U.2 SSD verwendet für das Feinabstimmungstraining von Llama 405B.
Starten Sie mit aiDAPTIV+ und erreichen Sie mehr.
aiDAPTIV+ bietet einen wichtigen Weg zur Erweiterung des verfügbaren Speichers für das Feinabstimmungstraining. Angesichts des weltweiten DRAM-Mangels und der damit einhergehenden Preissteigerungen ermöglicht es dies zu einem Bruchteil der Kosten. Es eröffnet das Potenzial, KI auf allen Unternehmensebenen zu nutzen, indem es lokale Hardware verwendet, die keine massiven Investitionen, kein Rechenzentrum und keine großen Mengen an Strom erfordert. aiDAPTIV+ eignet sich für Forschungs- und Bildungseinrichtungen und ermöglicht das Experimentieren mit größeren Modellen ohne teure Cloud-Verträge oder Bedenken hinsichtlich der Datensouveränität.
Phisons SC25-Demonstration beweist, dass für die Arbeit mit den größten KI-Modellen kein riesiges Rechenzentrum und keine kostspielige Infrastruktur erforderlich sind. aiDAPTIV+ bietet einen praktischen und kostengünstigen Weg zur Feinabstimmung von Modellen, die bisher Hyperscalern vorbehalten waren. Dies wird durch die Kombination von speziell entwickelten aiDAPTIVCache-SSDs mit intelligenter Speicherorchestrierung erreicht. Für Unternehmen, die größere Modelle nutzen und echte On-Premises-KI-Unabhängigkeit erreichen möchten, stellt aiDAPTIV+ eine überzeugende Neuerung dar.
Besuchen Sie Phison Erkunden Sie, wie aiDAPTIV+ Ihre KI-Workflows verändern kann und erleben Sie die Technologie in Aktion.






