KI ist heute in der Wirtschaft allgegenwärtig – von Robotern zur automatisierten Entscheidungsfindung am Fließband über Chatbots im Kundenservice bis hin zur spontanen Preisoptimierung in Spitzenzeiten im Energiesektor. In den Nachrichten wird viel darüber berichtet, wie KI unsere Arbeitsweise und unsere Interaktion branchenübergreifend beeinflusst.
Was in letzter Zeit jedoch für viel Aufsehen sorgt, ist die spezifischere Nische der generativen KI, die Technologie, die beliebten Apps zur Inhalts-, Bild- und Videoerstellung wie ChatGPT, DALL-E und OpenAIs Sora zugrunde liegt. Generative KI, auch GenAI genannt, hat das Potenzial, Unternehmen deutlicher zu verändern als andere KI-Lösungen, die Unternehmen heute unterstützen – allerdings nur, wenn Unternehmen den richtigen Datenspeicher bereitstellen können, der die von der Technologie geforderte Kapazität und Leistung bietet.

Was ist generative KI?
Vereinfacht ausgedrückt: Generative KI ist KI, die völlig neue Inhalte generiert, seien es Chatbot-Antworten, Produktdesigns, Werbematerialien, Bilder oder Videomaterial. Zwar ist KI für ethisch fragwürdige Deepfakes verantwortlich, doch kann sie auch eingesetzt werden, um schriftliche Antworten oder Inhalte wie Lebensläufe oder Online-Profile zu automatisieren, innovative Arzneimittelwirkstoffe zu empfehlen, elektronische Chipdesigns zu optimieren, Musik oder Romane in bestimmten Stilen zu schreiben, die Synchronisation in Filmen präziser zu gestalten, neue Kunst in jedem gewünschten Stil zu schaffen, architektonische Entwürfe basierend auf bestimmten Parametern zu erstellen und vieles mehr.
Generative KI unterscheidet sich von anderen Arten der KI dadurch, dass sie von Komponenten wie den folgenden abhängt:
Große Sprachmodelle (LLMs)
Ein LLM ist ein Programm, das Text verarbeitet, zusammenfasst und generiert. Es wird anhand riesiger Datensätze – mit potenziell Billionen von Parametern – trainiert und kann lernen, Text und Kontext zu verstehen. LLMs haben maßgeblich dazu beigetragen, dass generative KI-Modelle die Inhaltserstellung deutlich verbessern konnten. Sie ermöglichen beispielsweise die Umwandlung von Text in Bilder oder Videos sowie die automatische Beschriftung von Bildern.
Generative Adversarial Networks (GANs)
Ein GAN besteht aus zwei neuronalen Netzwerken, die ständig miteinander konkurrieren, um auffällig künstliche Ergebnisse zu identifizieren. Ein Netzwerk fungiert als Generator, das andere als Diskriminator. Der Generator ist so programmiert, dass er falsche oder ungenaue Ergebnisse erzeugt, die korrekt aussehen, und der Diskriminator identifiziert, welche Ergebnisse falsch sind. Durch diesen Prozess – der keine menschliche Überwachung erfordert – verbessert der Generator die Erstellung realistischer Inhalte und der Diskriminator deren Erkennung. Mit der Zeit werden die generierten Inhalte immer realistischer, bis der Diskriminator keine Ungenauigkeiten mehr erkennen kann.
Transformatoren
Diese Art neuronaler Netzwerke ermöglicht es sehr großen Trainingsmodellen, riesige Datenmengen zu analysieren, die nicht vorher gekennzeichnet werden müssen. Das bedeutet, dass ein KI-Algorithmus Millionen oder sogar Milliarden von Textseiten durchforsten kann, um dem Modell tieferes „Wissen“ zu vermitteln. Transformatoren ermöglichen es Modellen, Zusammenhänge zwischen Wörtern in einem Text zu erkennen und zu verstehen – beispielsweise den Kontext zwischen einzelnen Sätzen in einem Buch. Modelle können auch Zusammenhänge und Kontexte zwischen bestimmten Proteinen oder chemischen Substanzen, Codezeilen und sogar DNA-Markern erkennen.
Im Gegensatz zu herkömmlicher KI, die typischerweise einer vorgegebenen Reihe von Schritten folgt, um Daten zu analysieren und Ergebnisse zu generieren, ermöglicht generative KI dem Benutzer in der Regel die Eingabe einer Eingabeaufforderung oder Abfrage, um mit der Inhaltsgenerierung zu beginnen. Sie können die Anwendung beispielsweise bitten, einen kurzen Aufsatz über die Ereignisse vor dem Zweiten Weltkrieg zu verfassen. Fordern Sie Originalkunstwerke an, die das alltägliche Leben im Australien des 18. Jahrhunderts darstellen. Oder beschreiben Sie eine Szene im Text und erleben Sie, wie sie in einem realistischen Video zum Leben erweckt wird. Generative KI ist für die Erstellung neuer Inhalte konzipiert, nicht für die Ausführung von Aufgaben nach Regeln und voreingestellten Ergebnissen.
Wie GenAI funktioniert – und warum Datenspeicherung wichtig ist
KI jeglicher Art erfordert typischerweise enorme Datenmengen, und generative KI benötigt wahrscheinlich sogar noch mehr. KI-Projekte, einschließlich GenAI, durchlaufen zwei Phasen, und in jeder Phase müssen Forscher riesige Datensätze verwalten und verarbeiten.
Trainingsphase
Um generative KI-Algorithmen zu trainieren, füttern Forscher sie mit riesigen Datenmengen. Dazu gehören Online-Inhalte, Bücher, Videos, Bilder, Berichte, Social-Media-Inhalte und vieles mehr. Die KI-Plattform muss diese Daten speichern können. Der KI-Algorithmus analysiert diese Inhalte und identifiziert Zusammenhänge, Kontexte, Muster usw. Er erstellt mathematische Modelle basierend auf diesen Mustern und Zusammenhängen und verfeinert diese kontinuierlich mit zunehmenden Daten. LLMs vertiefen sich immer wieder in ihre Datensätze, um das Verständnis und das Bewusstsein für Muster und Bedeutungen zu verbessern.
Die durch das KI-Training entstehenden Workloads sind enorm und komplex. Sie erfordern höchste Leistung beim gleichzeitigen Lesen und Schreiben im Speicher. Die Hard- und Software, die diese Workloads unterstützt, muss mithalten können.
Inferenzphase
Nachdem ein GenAI-Algorithmus trainiert wurde, steht er Benutzern für Abfragen und Inhaltsausgaben zur Verfügung. Diese Aufgaben erfordern leistungsstarke Lesefunktionen, da das KI-System die Abfrage auf Milliarden oder Billionen von Parametern im Speicher anwenden muss, um in Sekundenschnelle die optimale Antwort zu generieren. Diese Phase erfordert zudem parallele Datenpfade, um die von den Benutzern erwartete Geschwindigkeit und Leistung zu erreichen.
Zu berücksichtigende Datenspeicherfaktoren für generative KI
Um den enormen Speicherbedarf der generativen KI zu decken, müssen Unternehmen ihre Datenspeicherungs- und -verwaltungspraktiken überdenken. Viele Unternehmen entscheiden sich für einen hybriden Ansatz zur Datenspeicherung und nutzen die Vorteile von Cloud- und On-Premise-Speicher, um KI-Projekte zu ermöglichen.
KI-freundliche Datenspeicherung umfasst typischerweise Folgendes:
-
-
- Hohe Kapazität – Petabyte sind ein Ausgangspunkt
- Ultrahohe Leistung – ermöglicht durch geringe Latenz und hohe IOPS und Durchsatz
- Parallelverarbeitung – ideal an große Rechner-Arrays und mehrere unabhängige Netzwerke angebunden
-
Um die Leistung zu erreichen, die generative KI erfordert, setzen viele Unternehmen auf Flash-basierte SSDs für ihre lokalen Arrays. Festplattenlaufwerke können zwar auch zur Speicherung von KI-Daten verwendet werden, Flash gilt jedoch als optimal. Tatsächlich ein Experte von NAND Research, einem Branchenanalyseunternehmen, erklärte kürzlich: „[Unternehmen], die es mit großen Sprachmodellen ernst meinen, kaufen High-End-Flash-Speicher.“
Mit SSDs können Unternehmen die benötigten hohen IOPS auf kleinerem Raum und mit geringerem Energieverbrauch bereitstellen. SSDs eignen sich auch gut für leistungsstarke Objektspeicher, die typischerweise für KI-Projekte verwendet werden.
Sogar Hyperscaler wie AWS, Azure und Google Cloud Platform setzen auf Flash-basierte Systeme mit SSDs, um die von den Kunden gewünschte Leistung zu bieten.
Phison bietet innovativen Datenspeicher für generative KI
Da Unternehmen zunehmend den Wert generativer KI und deren Nutzen für ihr Geschäft erkennen, investiert Phison weiterhin in Forschung und Entwicklung sowie Innovation, um ihren wachsenden Bedarf an Datenspeicherung zu decken.
Phison kennt sich mit KI aus und weiß, welche Speicherkapazitäten für den Erfolg erforderlich sind. Zu diesem Zweck hat das Unternehmen IMAGIN+ eingeführt, einen proprietären Anpassungsservice, der KI-Rechenmodelle und Lösungen für KI-Dienste umfasst.
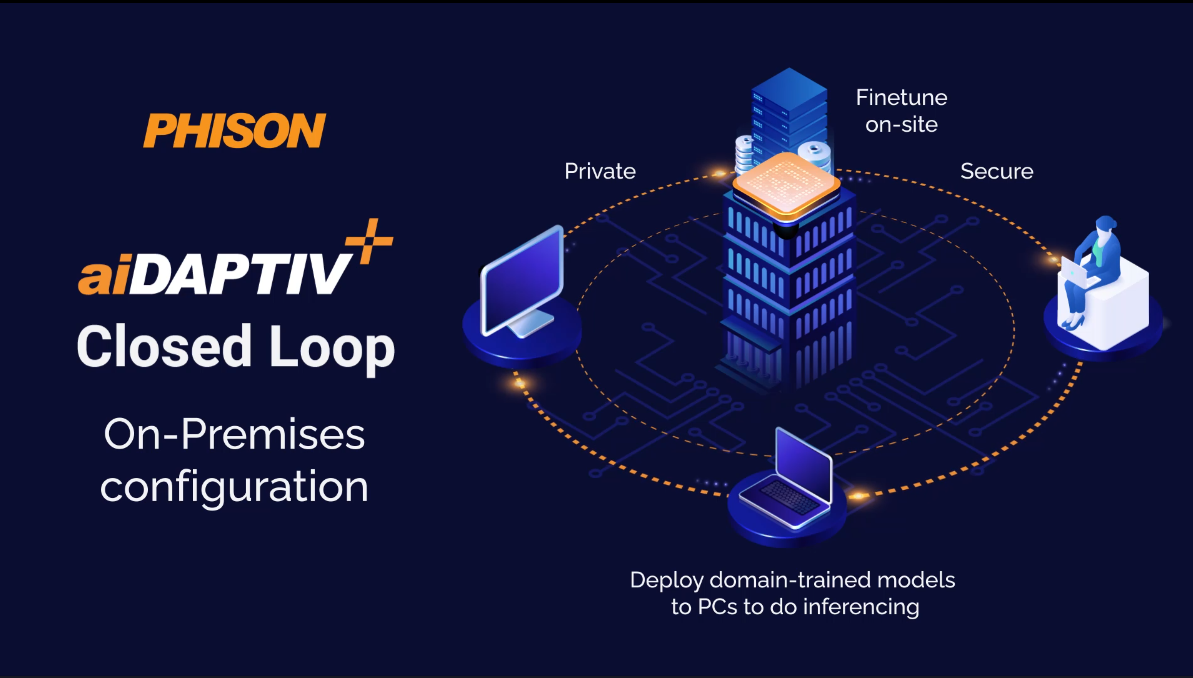
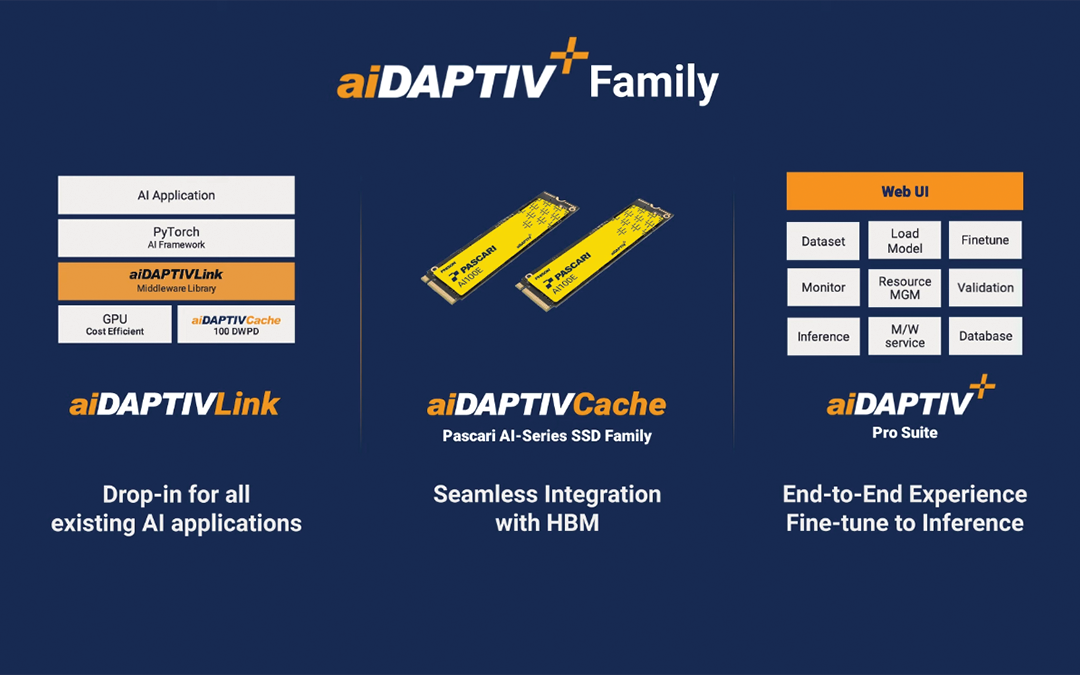
Das Unternehmen führte außerdem aiDAPTIV+, eine Erweiterung von IMAGIN+. Die neuen Dienste nutzen Phisons „innovative Integration von SSDs in das KI-Computing-Framework und erweitert NAND-Speicherlösungen im KI-Anwendungsmarkt.“
Durch die Integration von SSDs in das KI-Computing-Framework trägt Phison dazu bei, die Betriebsleistung von KI-Hardwarelösungen zu verbessern und die Kosten von KI-Projekten durch die Reduzierung der Abhängigkeit von GPUs und DRAM zu senken. Phison SSDs können als Offload-Support dienen und ermöglichen es Unternehmen, ihre generativen KI-Modelle mit geringerem Bedarf an GPUs und DRAM zu trainieren.
Mit den aiDAPTIV+-Lösungen von Phison können Unternehmen jeder Größe von generativer KI profitieren und gleichzeitig die Kontrolle über ihre proprietären Daten behalten. Unternehmen müssen nicht mehr Millionen von Dollar in die Anschaffung spezialisierter Hardware und GPUs investieren, um KI anhand ihrer Daten zu trainieren.
Generative KI hat das Potenzial, Geschäftsabläufe, Produktdesign, Kundenservice, Marketing und vieles mehr branchenübergreifend grundlegend zu verändern. Mit Flash-Speicher und SSDs von Phison können Sie Ihr Unternehmen auf diese Transformation vorbereiten.
Zusätzliche KI-Inhalte von Phison